本文目录
[[toc]]
基础命令
新增数据
// 往 home 集合中插入一条数据
// home 是集合名称,用于整合同类的数据文档
db.home.insertOne({ "name": 'He110' })
// 插入多条数据
db.home.insertMany([
{ "name": 'He110' }
])查找数据
// 单条件查询
db.movies.find({
"year": 1976
})
// 多条件 and 查询
db.movies.find({
"year": 1967,
"title": "红色娘子军"
})
// 多条件 and 查询严格意义上的写法
db.movies.find({
$and: [
{ "year": 1967 },
{ "title": "红色娘子军" }
]
})
// 多条件 or 查询
db.movies.find({
$or: [
{ "year": 1967 },
{ "title": "红色娘子军" }
]
})
// 正则匹配
db.movies.find({
"title": /红色/
})
// 逻辑比较
db.movies.find({
"year": {
// 不等于
$ne: 1,
// 大于
$gt: 1967,
// 大于等于
$gte: 1967,
// 小于
$lt: 1976,
// 小于等于
$lte: 1976,
}
})
// 其他条件
db.movies.find({
// 查找不存在 year 字段的数据
"year": {
$exists: false
},
})
db.movies.find({
"year": {
// 查找 year == 1967 或者 year == 1976
$in: [1967, 1976],
// 查找 year != 1978
$nin: [1978],
},
// 查询 from.country 字段 === "china"
"from.country": "china",
// 将属性值拆出来写
"from": {
// 定义的属性都要匹配
$elemMatch: {
"country": "china",
"city": "beijing",
}
}
})
// 只获取指定字段
db.movies.find(
{ "year": 1967 },
// 不返回 _id ,只返回 title
{ "_id": false, "title": true }
)删除数据
// 删除所有 year < 0 的数据
db.movies.remove({ "year": { $lt: 0 } })
// 删除所有数据
db.movies.remove({})
// 报错,必须给参数
db.movies.remove()更新数据
// 更新第一条匹配的数据
db.movies.updateOne(
// 查找哪些数据
{
"year": 1967
},
// 如何更新这条数据
{
$set: 1976
}
)
db.movies.updateOne(
{},
{
// 追加这条数据到底部
$push: { "year": 1976, "title": "太阳" },
// 追加多条数据到底部
$pushAll: [{ "year": 1976, "title": "太阳" }],
// 存在则不操作,不存在就插入
$addToSet: { "year": 1976, "title": "太阳" },
// 从指定数据中删除数据, 1 表示删除最后一个, -1 表示删除第一个
$pop: { "tags": 1 },
// 按值删除,而不是按序号
$pull: { "tags": "糟粕" },
// pull 的批量操作
$pullAll: [{ "tags": "糟粕" }],
}
)
// 更新所有匹配的数据
db.movies.updateMany([
{ "year": 1967 }
])清空集合
db.movies.drop()聚合操作
db.users.aggregate([
// 查找条件
{ $match: { "gender": "男" } },
// 从哪一行开始
{ $skip: 100 },
// 取多少数据
{ $limit: 20 },
{
$project: {
// first_name 字段重命名为 名
"名": "$first_name",
// last_name 字段重命名为 姓
"姓": "$last_name"
}
}
])上述命令等价于如下 SQL:
SELECT
first_name as '名',
last_name as '姓'
FROM Users
WHERE gender='男'
SKIP 100
LIMIT 20数据展开
db.students.findOne()
// {
// name: '张三',
// score: [
// { subject: '语文', score: 120 },
// { subject: '数学', score: 120 },
// { subject: '英语', score: 120 },
// ]
// }
db.students.aggregate([
{ $unwind: '$score' }
])
// {
// name: '张三',
// score: { subject: '语文', score: 120 }
// }
// {
// name: '张三',
// score: { subject: '数学', score: 120 }
// }
// {
// name: '张三',
// score: { subject: '英语', score: 120 }
// }分组
db.products.aggregate([
{
$bucket: {
// 按照 price 字段分组
groupBy: "$price",
// 分组区间为 [0, 10), [10, 20), [20, 30), [30, 40)
boundaries: [0, 10, 20, 30, 40],
// 不在区间内的放到 Other
default: "Other",
// 设定输出格式为 `{ count: 总数 }`
output: { "count": { $sum: 1 } }
}
}
])// 同时统计按 价格 和按 上市时间 分组的数据总量
db.products.aggregate([
{
$facet: {
price: {
$bucket: {
// 按照 price 字段分组
groupBy: "$price",
// 分组区间为 [0, 10), [10, 20), [20, 30), [30, 40)
boundaries: [0, 10, 20, 30, 40],
// 不在区间内的放到 Other
default: "Other",
// 设定输出格式为 `{ count: 总数 }`
output: { "count": { $sum: 1 } }
}
},
year: {
$bucket: {
// 按照 year 字段分组
groupBy: "$year",
// 分组区间为 [2021, 2022), [2022, 2023), [2023, 2024), [2024, 2025)
boundaries: [2021, 2022, 2023, 2024, 2025],
// 不在区间内的放到 Other
default: "Other",
// 设定输出格式为 `{ count: 总数 }`
output: { "count": { $sum: 1 } }
}
},
}
}
])数据计算
db.orders.aggregate([
// 声明数据的统计范围
{
$match: {
// 订单完成了才统计
status: "completed",
// 设置统计的时间段
orderDate: {
// 统计 2024 全年数据
$gt: ISODate("2025-01-01"),
$lte: ISODate("2024-01-01"),
},
}
},
// 聚合总金额、总运费、总数量
{
$group: {
// 所有数据聚合到一起,不分组
_id: null,
// total 字段等于每个数据的 total 相加
total: { $sum: "$total" },
// shippingFee 字段等于每个数据的 shippingFee 相加
shippingFee: { $sum: "$shippingFee" },
// 每次都 + 1
count: { $sum: 1 }
}
},
// 声明输出格式
{
$project: {
// 计算总利润
grandTotal: {
// 总利润 = 总金额 - 运费
$add: ["$total", "$shippingFee"]
},
// count 字段保留,继续输出
count: 1,
// _id 字段抛弃,不输出了
_id: 0
}
},
])复制集
机制
- 在数据写入时,将数据复制到其他独立节点上
- 在写入节点故障时,自动通过选举产生新的替代节点
由于以上机制,所以 MongoDB 也就拥有以下能力:
- 数据分发: 异地数据同步,减少另一个区域的读延迟
- 读写分离: 不同类型的操作在不同的节点上执行
- 异地容灾: 数据中心故障时可以快速切换到异地的备用数据中心
典型结构
一般 MongoDB 会组成三节点集群:
- 主节点: 只有一个,只有主节点能写
- 从节点: 两个或者多个,复制主节点中的数据,提供数据读操作
每个节点都可以参与选举投票,除此之外还有投票节点 Arbiter ,用于在平票时修改投票结果,但是现在已经不推荐使用了。
数据复制
- 主节点: 写入数据后,记录到 oplog 中
- 从节点: 获取主节点 oplog ,在本地回放主节点操作,同步更新数据
选举
具有投票权的节点之间两两发送心跳包,如果超过 5 次丢失心跳包则判断为节点失联。
如果失联的是从节点,则忽略。
如果失联的是主节点,触发选举。
选举基于 RAFT 一致性算法 实现,选举成功的必要条件是大多数投票节点存活。
复制集最多支持 50 个节点,但是具有投票权的节点最多 7 个。
被选举为主节点必须具备以下条件:
- 能够与多数节点建立连接
- 具有较新的 oplog
- 具有较高优先级(看是否有配置)
复制集节点支持以下配置:
v: 是否有投票权,有则参与投票priority: 指定节点优先级,优先级高的越优先成为主节点。 优先级为 0 无法成为主节点hidden: 节点可以复制数据,但是对应用不可见,优先级必须为 0 ,可以有投票权。 主要用于备份操作。slaveDelay: 手动设置同步时延,同步 N 秒之前的数据,保持时间差。 主要用于误操作时回滚。
复制集配置
# /data/db/mongod.conf
systemLog:
destination: file: # MongoDB 发送所有日志输出的目标指定为文件
path: /data/db/mongod.log # 日志文件地址
logAppend: true # 当 mongod 活着 mongo 实例重新启动时, mongod 或者 mongos 会将新条目附加到现有日志文件的末尾
storage:
dbPath: /data/db # 数据存放的目录
net:
bindIp: 0.0.0.0 # 监听的 IP
port: 28017 # 监听的端口
replication: # 指定为复制集模式,而不是单节点
replSetName: rs0 # 副本集的统一标识,有相同标识的 MongoDB 才能组成集群
processManagement:
fork: true # 作为独立后台进程运行,而不是在前台运行# 使用配置文件启动 MongoDB
mongod -f /data/db/mongod.conf# 进入创建的 mongo shell
# mongo 8 修改了命令为 mongosh ,如果是老版本使用 mongo
mongosh localhost:28017// 初始化集群,进入集群状态
rs.initiate()
// 查看集群状态,包括有哪些从节点
rs.status()
// 加入从节点
rs.add("localhost:28018")
// 加入从节点
rs.add("localhost:28018")通过父节点写入,从节点读取,可以验证复制集是否正常工作,需要注意的是,集群后从节点权限有所变化
// 从节点中,无法通过 shell 读取,需要先开启读权限
rs.slaveOk()
// 可以开始读操作了常见命令
// 从节点中,无法通过 shell 读取,需要先开启读权限
rs.slaveOk()
// 锁定写入或者同步操作,不会再更新数据,相当于已经宕机
db.fsyncLock()
// 解锁写入或者同步操作,恢复后会通过 oplog 回放同步数据,需要确保 oplog 数据完整,存放了从锁定到解锁期间的全部数据
db.fsyncUnlock()数据模型设计
模型设计需要考虑的元素:
- 实体 ( Entity ): 描述业务的主要数据集合。比如 Person 就是一个抽象出来的实体。
- 属性 ( Attribute ): 描述实体里面的单个信息。比如 name 就是 Person 实体的属性。
- 关系 ( Relationship ): 描述实体与实体之间的数据规则。比如 School 与实体就是多对多的关系。
SQL 三大范式
- 确保所有字段为原子值,数据不可再分。
- 每个非主属性完全依赖于主键,不依赖于主键的内容拆分出去其他表。
- 每个非主属性不依赖于其他非主属性,同时被多个表依赖的单独抽一个表,通过外键、关联表联系。
MongoDB 数据模型
传统数据建模经过“概念模型” -> “逻辑模型” -> “物理模型”。
- 在“概念模型”中,是对与用户需求的描述。
- 在“逻辑模型”中,将用户需求拆分为可落地的逻辑。
- 在“物理模型”中,考虑 SQL 设计范式,对数据按照范式建模。
MongoDB 可以直接跳过“物理模型”,直接对“逻辑模型”进行建模,因为 MongoDB 是允许冗余的,不需要原子性,也就没有额外的限制。
相对应的,在更新字段的时候,也需要考虑冗余字段一起更新。
MongoDB 模型设计
需要注意的是: 文档不能超过 16M ,如果嵌入后体积超了就必须进行拆分。
以联系人管理为例,进行建模。
建立基础模型
基础模型建立按照以下步骤:
- 找到需要存储的实体: 从“概念模型”中推导出“逻辑模型”。
- 明确实体间关系: 列出实体之间的关系。
- 确定数据内嵌方式: MongoDB 没有外键与关联表,转而通过数据冗余来处理,需要明确数据如何存放。
套用到联系人管理,即:
- 对象:
Contacts、Groups、Address、Avatars - 关系:
Contacts-Avatars: 一对一,每个用户一个头像。Contacts-Address: 一对多,每个用户可能有多个地址。Contacts-Groups: 多对多,每个用户可以属于多个组,每个组也可以有多个用户。
- 内嵌方式:
Avatars: 一对一直接整个对象作为子字段嵌入Contacts的数据结构即可。Address: 一对多也是直接嵌入对象中,作为数组存在。Groups: 作为数组内嵌对象中,用数据冗余实现多对多。
业务场景细化
明确以下需求,对模型进行调整:
- 最频繁的数据查询模式
- 最常用的查询参数
- 最频繁的数据写入模式
- 读写操作比例
- 数据量大小
在明确业务需求后, 使用引用来避免性能瓶颈,使用冗余来优化访问性能 。
关联表
需求:
- 联系人管理用于营销
- 有千万级别的联系人信息
- 分组会频繁修改,包括:新增分组、修改组名、修改分组描述、修改营销状态
- 一个分组可能会有百万级别的联系人
分析:
按照之前的模型,将 Group 嵌入 Contacts 中的话,会导致数据冗余,也就是会影响写操作的性能。
当 分组名 修改时,将会是百万级别的更新,所有属于同一组的数据都需要更新。
可以将 Group 单独拆分为一个集合,通过 group_ids 关联,查找时使用 $lookup 查询多个集合
查询示例:
db.contacts.aggregate([
{
$lookup: {
// 声明关联集合的名称
from: "groups",
// 使用本集合中哪个字段与关联集合匹配
localField: "group_ids",
// 使用关联集合的哪个字段与本集合匹配
foreignField: "group_id",
// 匹配后的 group 数据使用哪个键名储存
as: "groups"
}
}
])引用模式
需求:
- 用户上传高保真图片,大小为 5-10MB
- 上传头像一个月内不允许更换
- 不带头像查询与带头像查询的比例约为 9:1
分析:
由于头像本身不会被频繁读,并且内容很大,可以将其提取到单独的表中,使用引用的方式关联,让每次查询性能都能有较大的提升。
查询示例:
db.contacts.aggregate([
{
$lookup: {
// 声明关联集合的名称
from: "avatars",
// 使用本集合中哪个字段与关联集合匹配
localField: "avatar_id",
// 使用关联集合的哪个字段与本集合匹配
foreignField: "_id",
// 匹配后的 group 数据使用哪个键名储存
as: "avatar"
}
}
])总结
需要拆分出来单独存储的情况:
- 字段存储的数据较大,为 MB 级别或者超过 16MB
- 内嵌对象或者数组会被频繁修改
- 内嵌数组持续增长没有上限
$lookup 使用需要注意:
- MongoDB 不会对 lookup 的集合进行主外键检查
- 只支持
left outer join - 不能
from分片表
模型设计模式
分桶设计
- 场景: 记录时序数据,比如物联网、智慧城市、智慧交通
- 痛点: 数据点采集频繁,数据量大
- 方案: 通过内嵌文档,将碎片数据合并到一个实体中,减少索引大小与冗余数据占用
需求:
针对物联网场景下,海量无人机监控数据, 10w 架无人机,一年数据,每分钟记录一条。
{
_id: '20160101050000:CA2790',
icao: 'CA2790',
callsign: 'CA2790',
date: ISODate("2024-01-01T00:00:00.000+0000"),
event: {
a: 31428,
b: 173,
p: [115, 134],
s: 91,
v: 80
}
}记录的文档数: 100000 * 365 * 24 * 60 = 52560000000 ( 525.6 亿 ) 索引大小: 52560000000 * 130 = 6832800000000 ( 68328 亿 byte, 约 6364 GB ) 数据大小: 52560000000 * 92 = 4835520000000 ( 48355.2 亿 byte, 约 4503 GB )
也就是说,每年约 520 亿条数据,大小为 10TB
分桶设计的思路就是将数据聚合,每分钟数据聚合为每小时数据,也就是以下数据结构:
{
_id: '20160101050000:CA2790',
icao: 'CA2790',
callsign: 'CA2790',
events: [
{
a: 31428,
b: 173,
p: [115, 134],
s: 91,
v: 80,
date: ISODate("2024-01-01T00:00:00.000+0000")
},
{
a: 11111,
b: 222,
p: [-115, -134],
s: 91,
v: 80,
date: ISODate("2024-01-01T00:01:00.000+0000")
}
]
}修改后记录的文档数: 100000 * 365 * 24 = 876000000 ( 8.76 亿 ) 修改后索引大小: 876000000 * 130 = 113880000000 ( 1138.8 亿 byte, 约 106 GB ) 修改后数据大小: 876000000 * 92 = 80592000000 ( 805.92 亿 byte, 约 618 GB )
总体体积从 10TB 减少为 724GB 。
由于绝大多数情况下不会单独读取每分钟数据,在读取全天数据时,反而更有好处( 1440 次读取降低至 24 次 )
列转行
- 场景: 字段较多,每个字段都需要作为索引
- 痛点: 索引体积很大
- 方案: 关联字段合并为数组展示,这样索引数大幅降低
源数据结构如下:
{
title: 'Dunkirk',
release_USA: '2017/07/23',
release_UK: '2017/08/01',
release_France: '2017/08/01',
}列转行后:
{
title: '红色娘子军',
release: [
// 将列名转为 key 值
{
contry: 'USA',
date: '2017/07/23'
},
{
contry: 'UK',
date: '2017/08/01',
},
{
contry: 'France',
date: '2017/08/01',
}
]
}版本字段
- 场景: 数据结构频繁迭代,多种数据结构共存
- 痛点: 不同版本的数据存到一起,难以维护
- 方案: 添加版本号作为数据结构标识,针对不同数据版本做适配
近似计算
- 场景: 统计站点访问数据、点击数据,写远大于读
- 痛点: 频繁写,对 MongoDB 的读写分离模式不友好,压力全在 master 上
- 方案: 近似计算,比如每次取随机数 (0, 9) ,只要等于 0 就更新,一次更新给数据 + 10 ,哪怕数据不准确也不是很重要,对于性能的需求远高于准确性
预聚合字段
- 场景: 业绩排名、游戏排名、商品统计等精确统计
- 痛点: 消耗资源多,聚合计算时间长
- 方案: 额外存储统计数据,每次更新的时候,除了更新自身数据,再更新统计数据
{
product: 'milk',
sku: 'xxx-yyy-zzz-123456',
quantitiy: 12345,
// 统计的日销售额
daily_sales: 40,
// 统计的周销售额
weekly_sales: 40,
// 统计的月销售额
monthly_sales: 40,
}在销售的时候如下更新:
db.inventory.update(
{ _id: '123' },
{
$inc: {
// 库存 -1
quantity: -1,
// 统计字段 + 1
daily_sales: 1,
weekly_sales: 1,
monthly_sales: 1
}
}
)事务
写操作事务
writeConcern
writeConcern 决定需要写入多少节点,才算写成功,发起写操作的程序会被阻塞,直到写成功。
0: 发起写操作, master 写入就算写成功1-最大节点数: 需要被复制多少份,才能算写成功majority: 复制到超过半数节点上,才算写成功all: 写入全部节点,才算写成功
配置为 0 时可能会丢数据,在需要高性能低可靠性的场景才会使用,丢失数据的链路如下:
- 写入 master ,返回成功。
- master 挂起,剩下节点均未复制到该写操作。
配置为 1-最大节点数 时,由于 MongoDB 可能会动态扩容或者节点崩溃。
写死结点数并不是一个比较好的选择,可能由于节点挂起导致永远无法成功,也可能因为扩容后大多数节点未同步,导致数据丢失,一般不推荐设置。
配置为 majority 可以确保大多数节点均写入数据,但是对应的程序执行写操作的时间会变长。
配置为 all 可以绝对确保数据不丢失,但是对应的程序执行写操作的时间会变长,可能会成为响应瓶颈。
需要与 slaveDelay 综合考虑,避免因为手动限制延迟导致写操作时间延长
journal
MongoDB 的写操作分为两部分:
- 写入内存
- 写入磁盘
为了避免频繁磁盘 I/O ,写操作会先保存到内存中,在等到一定数量或者超时时间后,才会写入磁盘中持久化存储,一旦持久化存储了,即使宕机也不会丢失数据。
journal ,可以配置在何时确认写操作完成:
true: 必须写入磁盘才算完成。false: 写入内存就算完成。
注意事项
- 一般配置为
majority即可,兼顾性能与一致性。 - 尽量避免写死节点数,即使配置也不要配置全部节点,避免单点挂起导致所有写操作都失败。
writeConcern只是增加了程序写操作的时间,而不会增加MongoDB的写操作负载- 普通数据可以直接配置
{ w: 1 }即可,重要数据需要{ w: 'majority' }
读操作事务
由于 MongoDB 的分布式特性,读取数据会面临以下问题:
- 从哪个节点读?
- 什么数据可以读?
对应的可以通过以下配置来解决:
readPreferencereadConcern
readPreference
readPreference 决定了使用哪个节点进行读操作,可选值如下:
primary: 只选择主节点,适用于实时性要求极高的操作,只接受最新数据primaryPreference: 优先选择主节点,主节点不可用则读取从节点,适用于实时性要求较高的操作,偏好最新数据secondary: 只选择从节点,适用于实时性要求一般的操作,可以接受非最新数据secondaryPreference: 优先选择从节点,从节点不可用则读取主节点,适用于实时性要求一般的操作,可以接受非最新数据nesrest: 选择最近的节点,分布式异地集群考虑配置。${tag}: 根据节点Tag选择节点,可以通过给节点打Tag实现操作分离,需要大量读取数据的分发到性能较好的节点,普通操作可以直接使用次一级的节点,或者按照业务区分,避免业务互相影响。
readPerference 支持在初始化配置,在读之前配置等不同的配置方式:
- 通过MongoDB的连接串参数:
mongodb://host1:27107,host2:27107,h0st3:27017/?replicaSet=rs&readPreference=secondary - 通过MongoDB驱动程序APl:
MongoCollection.withReadPreference(ReadPreference readPref) - Mongo Shell:
db.collection.find(0).readPref("secondary") // 不管当前是什么节点,都从从节点读
注意事项:
- 尽量使用
primaryPreference替代primary,避免主节点挂起,还在选举中的时候,无节点可读。 - 使用
Tag需要考虑高可用问题,尽量为每个Tag配置多个节点 Tag需要与选举权、优先级综合考虑,一般有特定功能的Tag不希望成为主节点,设置优先级为 0
readConcern
在 readPreference 选择了指定的节点后, readConcern 决定这个节点上的数据哪些是可读的,类似于关系数据库的隔离级别。可选值包括:
available: 读取所有可用的数据local: 读取所有可用且属于当前分片的数据majority: 读取在大多数节点上提交完成的数据linearizable: 可线性化读取文档snapshot: 读取最近快照中的数据
available 与 local
在复制集中, available 与 local 无区别,在分片集中才有区别,也就是历史数据迁移到其他 MongoDB 中存储。
分片集中存在数据所有权概念,即当前数据属于哪个 MongoDB , available 不考虑所有权问题, local 要求所有权必须是自己。
在数据迁移分片的场景下,数据迁移过程中,所有权未变更,所以 available 与 local 就会表现不一致了。
注意事项:
local看起来更加可靠,但是每次读取都需要对数据进行过滤,在一些不太重要的场景下可以考虑切换为available- MongoDB <= 3.6 不支持从节点配置为
local - 从主节点读取数据时,默认为
local,从从节点读取数据时,为了向前兼容,默认为available
majority
只有大多数节点都 复制 了这条数据,这里的大多数是按照节点认知的大多数来确定的。
写操作到达大多数节点之前都是不安全的,一旦主节点崩溃,而从节还没复制到该操作,刚才的写操作就丢失了;把一次写操作视为一个事务,从事务的角度,可以认为事务被回滚了。
通过 majority 配置可以避免脏读问题,等同于 SQL 中的 Read Committed 。
majority 判断逻辑如下:
- 如果自身节点写入,但是大多数节点未写入,返回历史数据
- 如果自身节点写入,大多数节点写入,但是自身节点未收到其他节点的写入完成消息,返回历史数据
- 自身节点写入,且收到大多数节点的写入消息,返回新数据
MongoDB 会维护多个版本的数据快照,通过 MVCC 机制 来实现这套机制
开启 majority 需要在配置节点时就开启:
replication:
replSetName: rs0
enableMajorityReadConcern: truelinearizable
主节点失联,选举出新主节点,新主节点写入,此时读取老的主节点,由于通信断开,读取的还是老的数据,也就是脏数据, majority 无法避免这种情况。
此时需要使用 linearizable ,在读取的时候会与多数节点确认数据有效性,都认可数据有效了才会返回新数据。
该配置会导致读取效率降低,建议配合 maxTimeMS 设置超时时间,避免长时间阻塞。
snapshot
最高级别一致性,操作完成前,不能读到新数据,可以达到 SQL 中的 Repeatable Read
db.tx.insertMany([
{ x: 1 },
{ x: 2 },
])
var session = db.getMongo().startSession()
session.startTransaction({
// 设置读操作隔离性为最高级别
readConcern: { level: 'snapshot' },
// 设置写操作隔离性为 大多数 写入
writeConcern: { w: 'majority' },
})
var coll = session.getDatabase('test').getCollection('tx')
// 事务内查看数据
coll.find({ x: 1 }) // { x: 1 }
// 事务外更新数据
db.tx.updateOne({ x: 1 }, { $set: { y: 1 } })
// 事务外查看数据
db.tx.find({ x: 1 }) // { x: 1, y: 1 }
// 事务内查看数据
coll.find({ x: 1 }) // { x: 1 }
// 回滚数据
session.abortTransaction()事务开发
支持情况
| 事务属性 | 支持程度 |
|---|---|
| Atomocity 原子性 | 单表文档: 1.x 支持 复制集多表多行: 4.0 支持 分片集群多表多行: 4.2 支持 |
| Consistency 一致性 | writeConcern 、 readConcern 3.2 支持 |
| Isolation 隔离性 | readConcern 3.2 支持 |
| Durability 持久性 | Journal 与 Replication |
使用方法
db.tx.insertMany([
{ x: 1 },
{ x: 2 },
])
var session = db.getMongo().startSession()
session.startTransaction()
var coll = session.getDatabase('test').getCollection('tx')
// 事务内更新数据
coll.updateOne({ x: 1 }, { $set: { y: 1 } })
// 事务内查看数据
coll.find({ x: 1 }) // { x: 1, y: 1 }
// 事务外查看数据
db.tx.find({ x: 1 }) // { x: 1 }
// 回滚数据
session.abortTransaction()事务写机制
当一个事务开始后,如果事务要修改的文档在事务外部被修改过,则事务修改这个文档时会触发 Abort 错误,因为此时的修改冲突了。
这种情况下,需要将事务 abort 更新 timeline ,再重新开启事务。
如果一个事务已经开始修改一个文档,在事务以外尝试修改同一个文档,则事务以外的修改会等待事务完成才能继续进行。
注意事项
- 保证 MongoDB 版本大于 4.2 ,才能拥有完整的事务能力。
- 事务默认 60s 超时,超时的事务会被自动取消。
- 涉及事务分片不能使用仲裁节点。
- 事务会有额外性能开销,会影响 chunk 迁移效率, chunk 迁移也可能导致事务失效。
- 多文档事务中,必须使用主节点读取。
readConcern只应该在事务级别设置,不能设置在每次读写操作上。
MongoDB 最佳实践
连接 MongoDB
连接字符串中尽可能多的提供节点地址,建议全部列出,可以更有效的发现节点,完成集群,优先使用域名替代 IP
- 连接到复制集:
mongodb://节点1,节点2/database?[options], - 连接到分片集:
mongodb://mongos1,mongos2/database?[options]
常见的连接 options 参数:
maxPoolSize: 连接池大小maxWaitTime: 操作的最长等待时间,超出时间会被杀掉writeConcern: 建议为majority,保障数据安全readConcern: 在数据一致性要求高的情况下使用。
负载均衡
不建议在 MongoDB 之前实现负载均衡, MongoDB 本身就有负载均衡的能力。
如果提前进行负载均衡,可能有以下问题:
- 驱动无法探测节点存活,无法自动故障恢复
- 驱动无法判断游标在哪个节点创建,导致遍历游标错误。
游标
如果一个游标已经遍历完,则会自动关闭;如果没有遍历完,则需要手动调用 close() 方法,否则该游标将在服务器上存在 10 分钟(默认值)后超时释放,造成不必要的资源浪费。
但是,如果不能遍历完一个游标,通常意味着查询条件太宽泛,更应该考虑的问题是如何将条件收紧。
查询与索引
MongoDB 中没有进行资源隔离,如果某个操作缓慢,会影响所有的操作。
- 每一个查询都必须要有对应的索引
- 尽量使用覆盖索引 Covered Indexes
- 使用 projection 来减少返回到客户端的的文档的内容
写入
- 在 update 语句中只包含需要更新的字段
- 尽可能使用批量插入提高写入性能
- 使用 TTL 自动过期日志类型的数据
文档结构
- 防止字段名过长,占用存储空间
- 防止嵌套过深,超过 2 层就比较难以操作了
- 不要使用中文、标点符号等非拉丁字母作为字段名。
分页查询
- 避免使用
count查询总页数,count会遍历所有数据,拖慢查询速度 - 数据量大的时候,可以通过末尾元素
id过滤的方式提高查询效率:db.posts.find({ _id: { $gt: '上一页最后一个 _id' } }).sort({ _id: 1 }).limit(20)
事务
- 能不用就不用,事务本身就有额外开销,尽量通过模型设计规避事务
- 不要使用过大的事务,避免超时
- 必须使用时尽量让文档处在同一分片上
分片集群
集群架构
分片架构将数据分为不同的 chunk ,每个 chunk 交给一套复制集管理,这样可以有效分离读写压力,降低负载,也允许横向扩展。
分片集群的架构如下:
graph TB
subgraph Business[业务层]
App[Application]
Driver[MongoDB 驱动]
App --> Driver
end
subgraph MongoS
MongoS1[主 MongoS]
MongoS2[备用 MongoS 1]
MongoS3[备用 MongoS 2]
end
subgraph Config
Config1[主 Config]
Config2[从 Config 1]
Config3[从 Config 2]
end
Driver --> MongoS
Config --> MongoS
MongoS --> Config
subgraph Mongo1[Shard 1]
Mongo1-master[主节点]
Mongo1-slave1[从节点 1]
Mongo1-slave2[从节点 2]
end
subgraph Mongo2[Shard 2]
Mongo2-master[主节点]
Mongo2-slave1[从节点 1]
Mongo2-slave2[从节点 2]
end
subgraph Mongo3[Shard 3]
Mongo3-master[主节点]
Mongo3-slave1[从节点 1]
Mongo3-slave2[从节点 2]
end
MongoS --> Mongo1
MongoS --> Mongo2
MongoS --> Mongo3MongoS 是路由节点,提供集群的统一入口,将业务层请求分发到合适数据节点中操作,并将各个数据节点的响应结果合并。
由于是入口文件,为了防止集群崩溃,一般至少准备一台备用 MongoS
Config 是配置节点,提供汲取元数据存储、分片数据分布的映射等,提供比如数据存储路径、不同 shared 管理哪些范围的数据等等,一般是复制集架构即可。
Shard 为数据节点,以复制集为单位,可以横向扩展,数据节点最多 1024 个,所有数据节点之间的数据不重复。
分片方式
MongoDB 提供三种数据分布方式:
- 基于范围
- 基于 Hash
- 基于 zone / tag
基于范围
挑选部分字段,按照字段取值进行分片
- 优点:
- 查询性能好
- 查询相近数据基本在同一节点,速度快,比如按时间分片,按时间段查询。
- 缺点:
- 数据分布不均匀
- 容易有热点(某个分片频繁读写,其他分片闲置)
基于 Hash
挑选部分字段,按照字段值进行 Hash ,按照 Hash 结果进行分片
- 优点:
- 数据分布均匀
- 写数据可以分散到多个分片,效率高
- 缺点:
- 范围查询效率较低
基于 zone / tag
按照节点地域、节点标签分片
总结
分片架构可以有效解决性能问题与扩容问题,但是有大量额外资源开销,管理复杂,非必要不使用( MongoDB 官方统计数据,约 10% 会使用分片集群 )。
分片架构设计
分片基础标准:
- 数据量不要超过 3TB ,尽可能保持在 2TB 一个片
- 索引必须能放到内存中
分片估算:
- 存储: 所有的存储总量 / 单服务器负载容量
- 内存: 工作集大小 / (单服务器内存容量 * 0.6)
- 并发: 总并发数 / (单服务器并发数 * 0.7)
三者取最大值作为分片数量
分片概念
各种概念由小到大:
- 片键 shard key: 文档中的一个字段,用于决定数据存储到哪个分片中
- 文档 doc: 包含 shard key 的一行数据
- 块 Chunk: 包含 n 个文档;
- 分片 Shard: 包含 n 个 chunk
- 集群 Cluster: 包含 n 个分片
影响分片性能的主要因素
分片字段:
- 分片字段取值范围较大: 过小会导致数据集中,难以扩展
- 分片字段取值均匀: 尽量让不同分片的数据均匀分布,避免单独分片压力大
- 使用片键作为查询条件: 帮助 MongoS 快速定位需要查询哪个分片数据,否则 MongoS 需要查询每个分片数据
总结: 一般单独片键很难兼顾上述三个条件,所以会选用组合片键,比如 user_id + time 作为分片字段
读写:
- 分散写,集中读: 写尽量分散到不同分片中,避免复制集 master 过载;读尽量在同一分片中,减少数据读取、数据合并带来的开销
资源:
- mongos 与 config 可以使用较低配置,但是 Shard 需要使用较高配置
- 由于扩容也需要时间,比如数据迁移,重新分片等等,最好在资源负载 60% 就先开启扩容,避免影响业务
分片命令
创建分片复制集集
需要在同一分片中的设备都执行一次
# 监听 IP
mongod --bind_ip 0.0.0.0 \
# 分片集名称
--replSet shard1 \
# 分片集数据存储路径
--dbpath /data/shard1 \
# 分片集日志存储路径
--logpath /data/shard1/mongod.log \
# 监听的端口
--port 27010 \
# 后台运行
--fork \
# 表明为分片集节点
--shardsvr \
# 指定 MongoDB 缓存大小,按需配置
--wiredTigerCacheSizeGB 1初始化分片集中的复制集
通过 mongosh 连接到复制集任意节点,执行初始化即可,初始化后会自动进行选举
rs.initiate({
_id: 'shard1',
members: [
{
_id: 0,
host: 'member.he110.site:4395'
},
{
_id: 1,
host: 'member.he110.site:4396'
},
{
_id: 2,
host: 'member.he110.site:4397'
},
]
})创建 Config
需要在同一分片中的设备都执行一次
# 监听 IP
mongod --bind_ip 0.0.0.0 \
# 分片集名称
--replSet config \
# 分片集数据存储路径
--dbpath /data/config \
# 分片集日志存储路径
--logpath /data/config/mongod.log \
# 监听的端口
--port 27019 \
# 后台运行
--fork \
# 表明为分片集配置节点
configsvr \
# 指定 MongoDB 缓存大小,按需配置
--wiredTigerCacheSizeGB 1初始化 Config 中的复制集
通过 mongosh 连接到 Config 任意节点,执行初始化即可,初始化后会自动进行选举
rs.initiate({
_id: 'config',
members: [
{
_id: 0,
host: 'config.he110.site:4395'
},
{
_id: 1,
host: 'config.he110.site:4396'
},
{
_id: 2,
host: 'config.he110.site:4397'
},
]
})创建 MongoS
需要在同一 MongoS 集群中的设备都执行一次
# 监听 IP
mongos --bind_ip 0.0.0.0 \
# 分片集日志存储路径
--logpath /data/shard1/mongod.log \
# 监听的端口
--port 27010 \
# 后台运行
--fork \
# 指定配置节点
--configdb config/config.he110.site:4395,config.he110.site:4396,config.he110.site:4397添加分片
通过 mongosh 连接到 MongoS 主节点,执行以下命令
sh.addShard("shard1/member.he110.site:4395,member.he110.site:4396,member.he110.site:4397")创建分片集合
通过 mongosh 连接到 MongoS 主节点,执行以下命令
// 开启分片功能
sh.enableSharding('${db}')
// 创建分片集
sh.shardCollection(
// 哪个集合需要开启分片
'${db}.${collection}',
// 创建片键,支持多个字段
{
// 使用 id 作为片段,分片方式为 hash
_id: 'hashed',
},
)扩容
创建分片与前面一样,不需要再创建 Config 与 MongoS
创建完成后,连接到 MongoS ,将分片 2 通过 sh.addShard 添加进去即可, MongoS 会自动完成数据迁移
运维
性能监控
监控工具
进行性能监控常见工具有:
- MongoDB Ops Manager: 官方监控,企业版收费
- Percona
- 通用的服务器监控平台
- 程序脚本
监控数据来源
db.serverStatus(): 开机到现在的累计数据,主要的监控数据来源db.isMaster(): 次要数据来源mongostat: 命令行工具,只能查到一部分信息
serverStatus() 主要关注以下信息:
connections: 连接数信息locks: 使用锁的情况network: 网络 I/O 情况opcounters: CURD 执行次数统计repl: 复制集的配置信息wiredTiger: 包含 WirdTiger 执行情况信息block-manager: WT 数据块的读写情况session: session 使用数量concurrentTransactions: Ticket 使用情况
mem: 内存使用情况mertrics: 性能指标统计信息
告警指标
| 指标 | 意义 | 获取方法 |
|---|---|---|
opcounters(操作计数器) | 统计查询、更新、插入、删除、 getmore 等命令的数量 | db.serverStatus().opcounters |
tickets(令牌) | WiredTiger 存储引擎的读/写令牌数量,表示可以进入存储引擎的并发操作数 | db.serverStatus().wiredTiger.concurrentTransactions |
replication lag(复制延迟) | 写操作到达从结点所需的最小时间。过高的延迟会降低从结点价值,且不利于配置了写关注( w > 1 )的操作 | db.adminCommand({'replSetGetStatus': 1}) |
oplog window(复制时间窗) | 代表 oplog 可容纳写操作的时间范围,从结点离线后仍能追上主节点的最大时长(建议保持 24 小时以上) | db.oplog.rs.find().sort({$natural:-1}).limit(1).next().ts - db.oplog.rs.find().sort({$natural:1}).limit(1).next().ts |
connections(连接数) | 监控数据库连接数,每个连接消耗资源,需统计低峰/高峰时段的连接数并设置报警阈值 | db.serverStatus().connections |
Query targeting(查询专注度) | 计算每秒扫描的 索引键/文档数量 与 返回文档数 的比值,值高表示查询效率低(可能缺少索引或索引不当) | var status = db.serverStatus()status.metrics.queryExecutor.scanned / status.metrics.document.returnedstatus.metrics.queryExecutor.scannedObjects / status.metrics.document.returned |
Scan and Order(扫描和排序) | 每秒内存排序操作平均比例,内存排序可能消耗大量资源,通过索引可避免 | var status = db.serverStatus();status.metrics.queryExecutor.scanAndOrder / status.opcounters.query |
| 节点状态 | 监控各节点状态( PRIMARY / SECONDARY / ARBITER ),非正常状态或命令执行失败时报警 | db.runCommand("isMaster") 或 db.isMaster() |
dataSize(数据大小) | 实例数据总量(压缩前原始大小) | 逐个数据库执行:db.stats().dataSize |
StorageSize(磁盘空间大小) | 已用磁盘空间占总空间的百分比,需监控存储压力 | 通过文件系统工具计算,或使用 db.stats().storageSize 结合磁盘总容量推算 |
备份与恢复
备份的目的
- 防止硬件故障导致数据丢失
- 防止认为误删数据
- 时间回溯
- 监管要求
备份机制
- 延迟节点备份: 设置子节点
slaveDelay并且不参与选举,将节点作为备份节点 - 全量备份 + oplog 增量: 初始数据全量备份,通过 oplog 可以回放数据操作,实现任意时间点的数据还原。为了防止 oplog 过大,可以定期更正初始数据为较新状态,裁剪过期 oplog
全量备份方式
- 复制数据文件
- 必须先关闭节点,才能复制,否则复制的文件无效
- 可以通过
db.fsyncLock()锁定节点备份,通过db.fsyncUnlock()解锁 - 在从节点完成备份
- 注意节点被锁定后,投票节点总数需要保持奇数
- 文件系统快照
- MongoDB 支持使用快照获取某一时刻的镜像
- 快照过程可以不用停机
- 数据文件和 journal 需要在同一个卷上
- 尽快复制并删除快照,避免磁盘占用打满
- mongodump
- 备份速度最慢
- 只能备份某个时间段的数据
- oplog 需要从开始备份的时候记录,处理不停机备份导致的脏数据问题(备份过程中数据被修改)
mongodump 命令
# 开始备份,并记录 oplog
mongodump --host localhost:27017 --oplog
# 恢复数据,并通过 oplog 回放保证数据一致性
mongorestore --host localhost:27017 --oplogReplaymongodump 备份的目录结构
- dump: 备份文件目录
- db: 备份的数据库
- collection.bson: 备份的集合数据
- collection.metadata.bson: 备份的集合元数据
- oplog.bson: 备份期间的 oplog
- db: 备份的数据库
安全架构
认证
用户认证:
| 认证方式 | 描述 | 备注 |
|---|---|---|
| 用户名 + 密码 | 默认认证方式,使用 SCRAM-SHA-1 哈希算法,用户信息存于 MongoDB 本地数据库 | 无 |
| 证书方式 | 基于 X.509 标准: 服务端需提供证书文件启动 、 客户端需证书文件连接 、 支持内部或外部 CA 颁发的证书 | 无 |
| LDAP外部认证 | 连接到外部 LDAP 服务器进行认证 | 企业版功能 |
| Kerberos外部认证 | 连接到外部 Kerberos 服务器进行认证 | 企业版功能 |
集群节点认证:
- Keyfile: 将同一 Keyfile 拷贝到不同的节点
- X.509: 基于证书认证,推荐不同节点使用不同证书
创建管理员账号:
// 跳转到 admin 集合
use admin;
// 创建用户 admin ,密码为 123456 ,拥有管理所有用户、数据库、读写权限
db.createUser({
user: "admin",
pwd: "123456",
roles: [
{ role: "userAdminAnyDatabase", db: "admin" },
{ role: "dbAdminAnyDatabase", db: "admin" },
{ role: "readWriteAnyDatabase", db: "admin" }
]
})使用账号登录
mongosh \
# 用户名,可以简写为 -u
--username admin \
# 密码,可以简写为 -p
--password abc123456 \
# 需要操作的数据库
--authenticationDatabase admin鉴权
基于角色的权限控制,通过 db.getRole('角色名') 获取角色信息,通过 db.getRole('角色名', { showPrivileges: true }) 获取角色以及权限信息,权限保存在 privileges.actions 字段中
graph TD
classDef app fill:#ffd6e7,stroke:#ff69b4
classDef db fill:#e6f4ff,stroke:#1890ff
classDef backup fill:#b3e0ff,stroke:#096dd9
classDef root fill:#f0f0f0,stroke:#666
%% 权限关系图
root("root<br>(超级用户角色)")
subgraph 全局管理
readAnyDB["readAnyDatabase"]
writeAnyDB["readWriteAnyDatabase"]
adminAnyDB["dbAdminAnyDatabase"]
userAnyDB["userAdminAnyDatabase"]
end
root --> readAnyDB["readAnyDatabase"]
root --> writeAnyDB["readWriteAnyDatabase"]
root --> adminAnyDB["dbAdminAnyDatabase"]
root --> userAnyDB["userAdminAnyDatabase"]
subgraph 备份恢复
backup
restore
end
root --> restore
subgraph 数据库管理
dbOwner --> dbAdmin
dbOwner --> userAdmin
end
subgraph 集群管理
ClusterAdmin --> hostManager
ClusterAdmin --> clusterManager
ClusterAdmin --> clusterMonitor
end
root --> ClusterAdmin
subgraph 应用程序用户
readWrite --> read
end
%% 权限继承关系
readAnyDB --> read
writeAnyDB --> readWrite
adminAnyDB --> dbAdmin
userAnyDB --> userAdmin
%% 样式绑定
class root root
class GlobalAdmin,readAnyDB,writeAnyDB,adminAnyDB,userAnyDB db
class BackupRestore,backup,restore backup
class DBAdmin,dbAdmin,userAdmin,dbOwner db
class ClusterAdmin,hostManager,clusterManager,clusterMonitor db
class AppUser,read,readWrite app创建角色:
db.createRole({
role: 'sampleRole',
// 声明角色具有的权限
privileges: [
{
// 允许操作 test.sample
resource: {
db: 'test',
collection: 'sample'
},
// 允许进行更新
actions: ['update']
},
],
// 继承其他角色的权限
roles: [
// 继承 read 角色的读权限,允许读取 test 数据库
{
role: 'read',
db: 'test',
},
],
})加密
- 通信加密: MongoDB 允许通过 TLS/SSL 加密所有网络传输,包括客户端与服务端、内部复制集之间
- 存储加密: 企业版 MongoDB 支持在持久化到磁盘时,对数据进行加密,具体流程为如下
- 生成 master key ,用来生成每一个数据库的 key
- 每一个数据库的 key ,用来加密数据库
- 基于生成的数据库 key ,加密数据库中的数据
- 管理时只需要关注 master key 即可,数据库 key 保存在数据库内部
- 字段加密: 单独字段可以通过自身密钥加密,数据库中只能看到密文,全程由 MongoDB 自动操作,具体流程如下
- 请求 MongoDB 驱动加密字段
- MongoDB 驱动查询密钥管理器
- 密钥管理器返回密钥
- MongoDB 驱动查询数据库
- 数据库返回加密后的数据
- 使用密钥解密数据,返回给用户
审计
审计功能可以针对特定的行为进行记录,必须购买企业版才支持
- 格式: json
- 存储: 本地文件或者 syslog
- 内容:
- Schema change ( DDL )
- CURD (DML)
- 用户认证
# 监听 IP
mongod --bind_ip 0.0.0.0 \
# 分片集数据存储路径
--dbpath /data/config \
# 分片集日志存储路径
--logpath /data/config/mongod.log \
# 监听的端口
--port 27019 \
# 后台运行
--fork \
# 审计日志记录到 syslog 另一个可选值为 file
--auditDestination syslog \
# 存储的审计文件格式,配置为 syslog 后不需要配置
--auditFormat JSON \
# 配置审计文件存放路径,配置为 syslog 后不需要配置
--auditPath /data/audit \
# 审计文件内容,这里是审计创建集合与删除集合
--auditFilter '{ atype: { $in: [ "createCollection", "dropCollection" ] } }'最佳实践
默认情况下 MongoDB 没有安全设置,也没有鉴权,需要手动创建用户并且关闭
- 启用身份认证
- 严格权限控制
- 加密传输、加密数据、活动审计
- 内网部署服务器,并部署防火墙、关闭 http 访问、关闭 restful 访问、绑定 IP 、替换默认端口等等
- 遵循当地合规需求
索引机制
术语表
Index: 索引。通常为某条记录的字段。
Key: 键名。每条记录所有的字段都是键名。
Data Page: 数据页。存储记录的地方。
Covered Query: 查询覆盖。指查询的所有字段都在索引中,不需要从数据页中加载数据。
FETCH: 抓取。指按照索引,在数据页中查询对应的记录。
IXSCAN: 索引扫描。检索索引。
COLLSCAN: 集合扫描。检索数据页。
Query Shape: 查询条件的数据结构。不同的查询条件对查询性能也有影响。
Index Prefix: 索引前缀。指多个键名索引时,所有的查询前缀都会被索引,不需要再添加索引了,比如
{ a: 1, b: 1, c: 1 },会自动添加{ a: 1, b: 1 }已经{ a: 1 }的索引Selectivity: 过滤性。优先使用能过滤绝大多数数据的条件进行查询。
索引存储结构
索引存储使用 B- 树 , 一般 B 树是二叉树, B- 树可以是多叉树
索引的执行
查询条件命中多个索引时,会通过多线程查询几条记录,哪个查的快用哪个,所以可能会使用慢速索引(索引对应的数据较多)
graph TB
classDef orange fill:#FFA500,stroke:#FF4500,color:white
classDef green fill:#98FB98,stroke:#32CD32
classDef diamond fill:#FFD700,stroke:#DAA520
%% 流程节点
start[("查询语句")]:::orange --> match{匹配计划缓存}
%% 匹配成功分支
match -- Y --> evaluate{评估计划性能}:::diamond
evaluate -- Y --> execute["按执行计划执行"]:::green
execute --> result["返回结果"]:::green
%% 评估不成功分支
evaluate -- N --> evict1["驱逐计划缓存"]:::green
evict1 --> generate1["生成候选计划"]:::green
generate1 --> assess1["评估候选计划"]:::green
assess1 --> select1["选择最优计划"]:::green
select1 --> create1["创建计划缓存"]:::green
create1 --> execute
%% 匹配失败分支
match -- N --> generate2["生成候选计划"]:::green
generate2 --> assess2["评估候选计划"]:::green
assess2 --> select2["选择最优计划"]:::green
select2 --> create2["创建计划缓存"]:::green
create2 --> execute查看执行过程
可以在查询语句后面追加 explain ,要求查看检索过程: db.col.find({ name: '张三' }).explain(true)
重点关注:
executionStages.stage: 是 COLLSCAN 还是 IXSCAN ,也就是有没有用到索引totalDocsExamined与nReturned: 查询了totalDocsExamined条文档能返回nReturned条数据totalKeysExamined: 查询了多少 keyexecutuionTimeMillis: 执行了多少毫秒
查询条件应该遵循 ESR 原则,使用: 精确匹配 > 排序条件 > 范围匹配 的顺序排列索引字段,如果字段无索引,放到最后面
索引类型
- 单键索引
- 组合索引
- 多值索引
- 地理位置索引
- 全文索引
- TTL 索引
- 部分索引
- 哈希索引
读写性能
驱动层
整体驱动工作流程图如下:
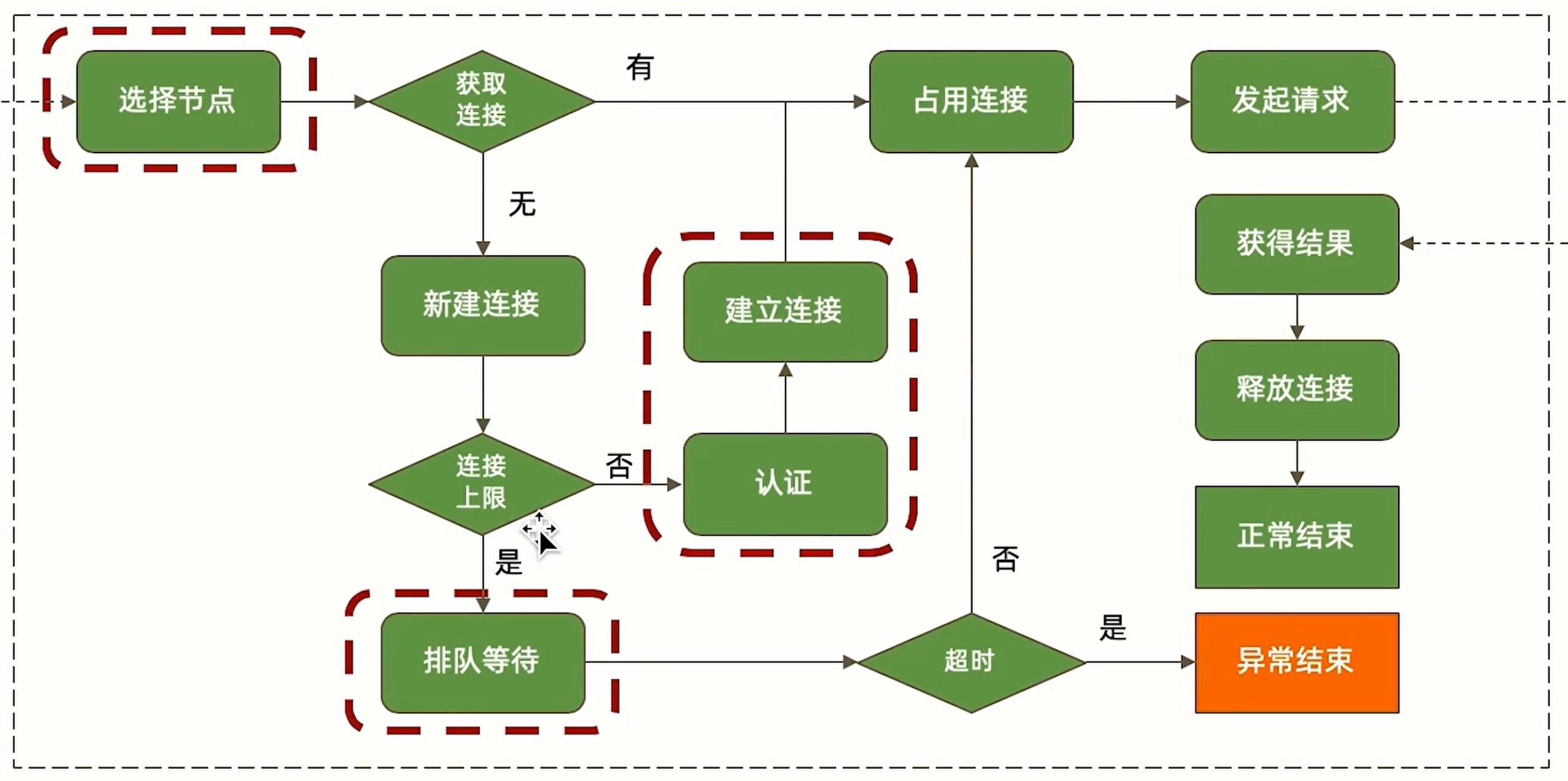
选择节点
对于复制集读操作,选择哪些节点是由 readPreference 决定的,如果不希望选中远距离节点,应该做到以下其中一条:
- 设置为隐藏节点
- 通过 Tag 控制候选节点
- 使用 nearest 就近选择节点
排队等待
总连接数大于最大连接数 ( maxPoolSize ) 就会发生排队等待,也就是阻塞情况。
可以采用以下方式解决:
- 加大最大连接数(受限于服务器性能,不一定有用)
- 优化操作性能,缩短操作时间
连接与认证
认证比不认证需要多消耗一些时间,但是认证才能保证安全,为了优化连接速度,可以采用以下方式:
- 设置最小连接数 ( minPoolSize ) ,在连接池中保持一定数量的空闲连接,可以直接复用不需要额外创建
- 在业务处理时,避免突发的大量请求
数据库层
整体数据库层工作流程图如下:
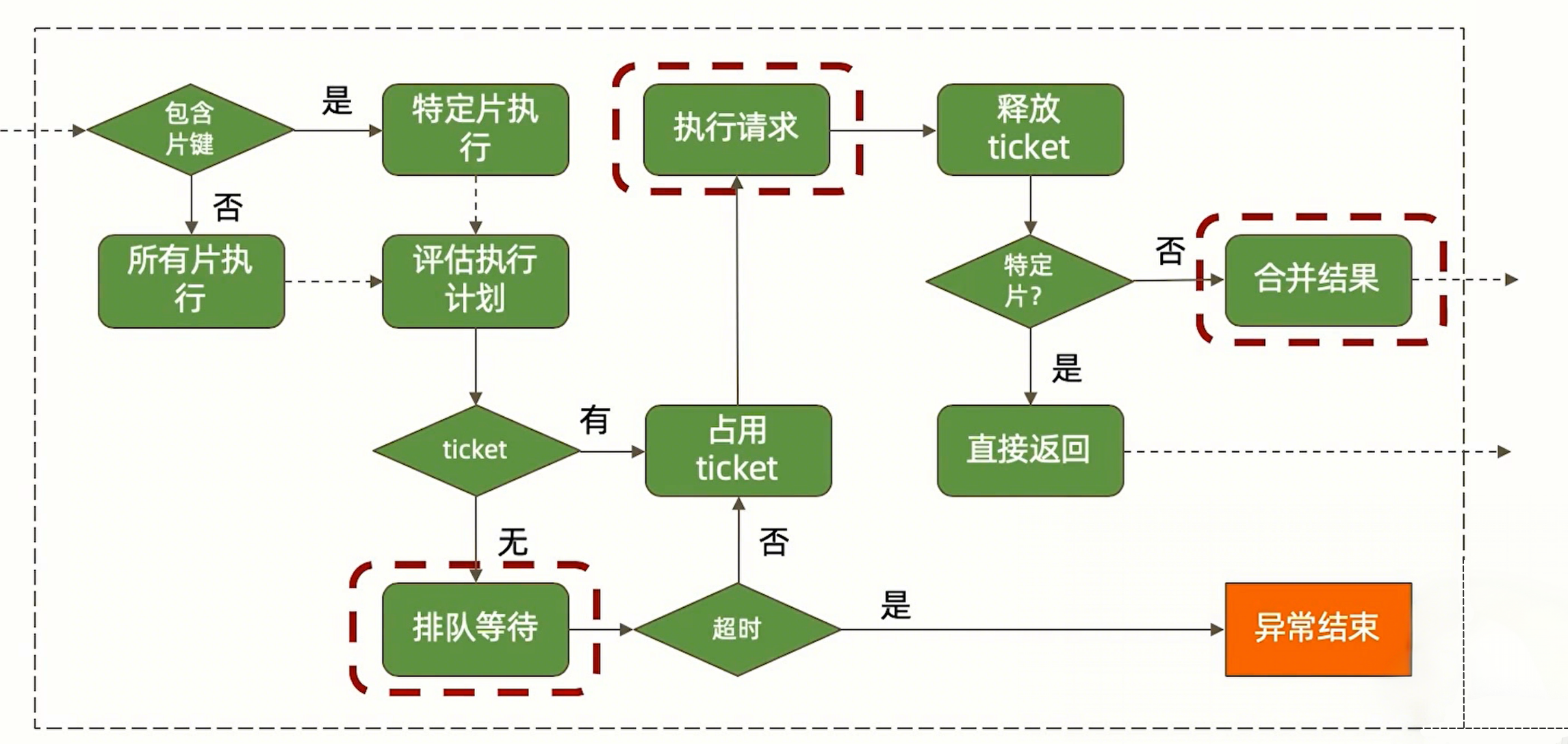
排队等待
ticket 不足导致数据库查询排队,一般是其他操作性能迟缓的问题,解决方案如下:
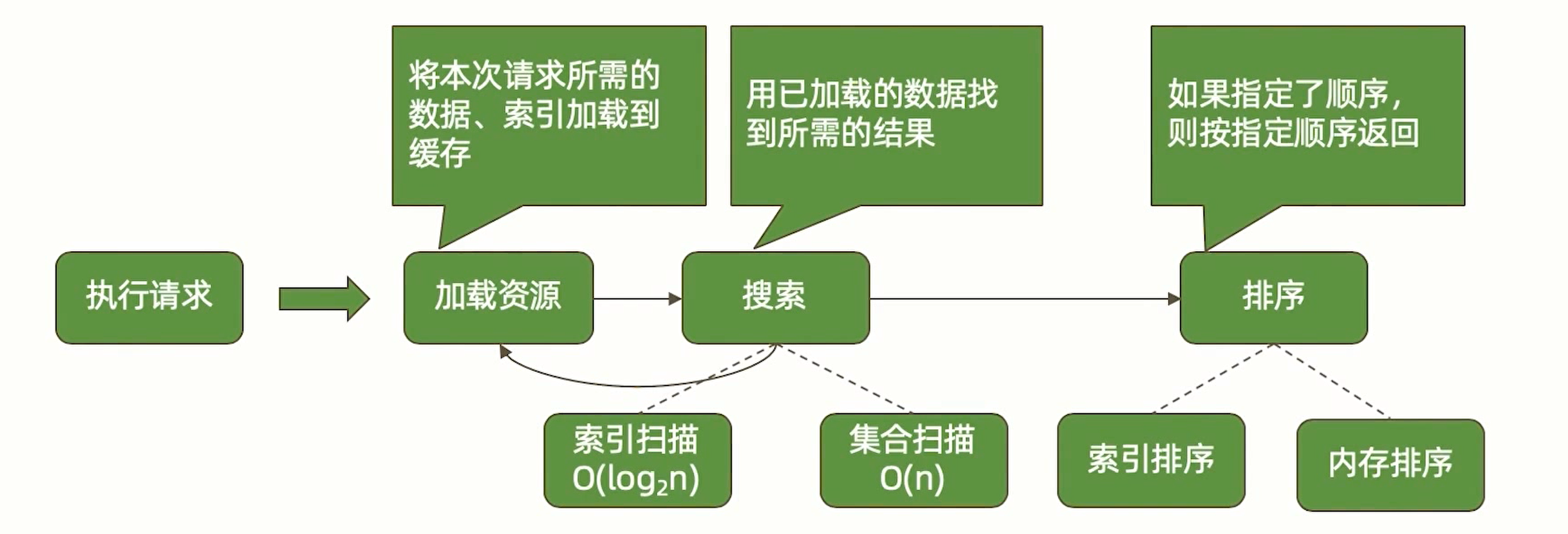
读请求
读请求迟缓的主要原因是由于索引导致的,可以参考 索引的执行 章节提到的索引工作过程,结合 explain 排查问题,优化索引。
写操作
写操作也需要利用索引找到需要修改的位置,如果写操作迟缓,也可以通过 explain 定位问题点,看是不是索引问题导致的。
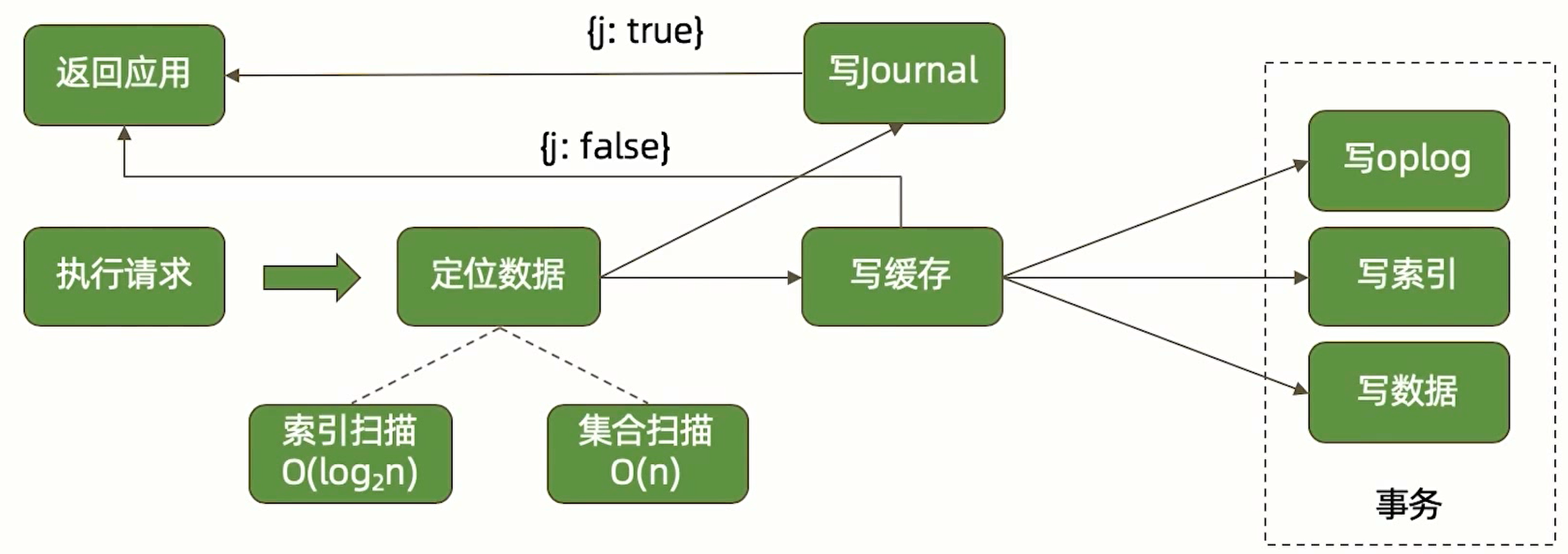
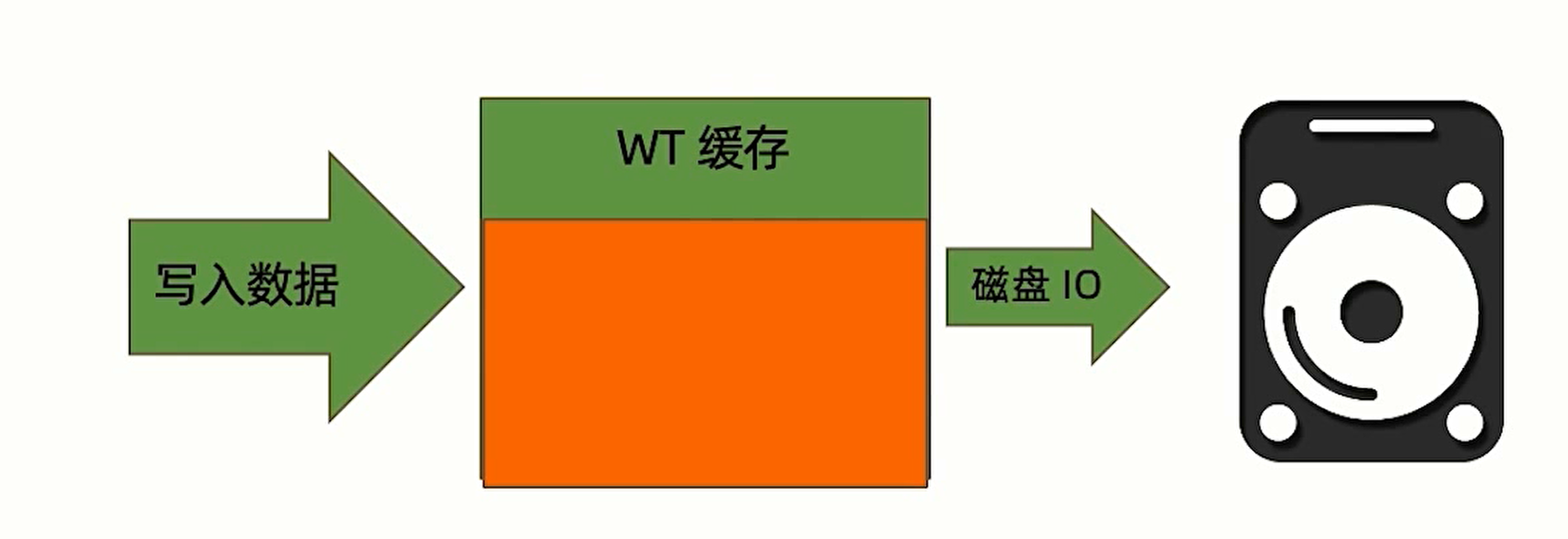
写数据需要利用 WT 缓存, WT 缓存在写入磁盘后失效,如果磁盘 I/O 性能低,缓存来不及被消费,也会导致写操作迟缓。
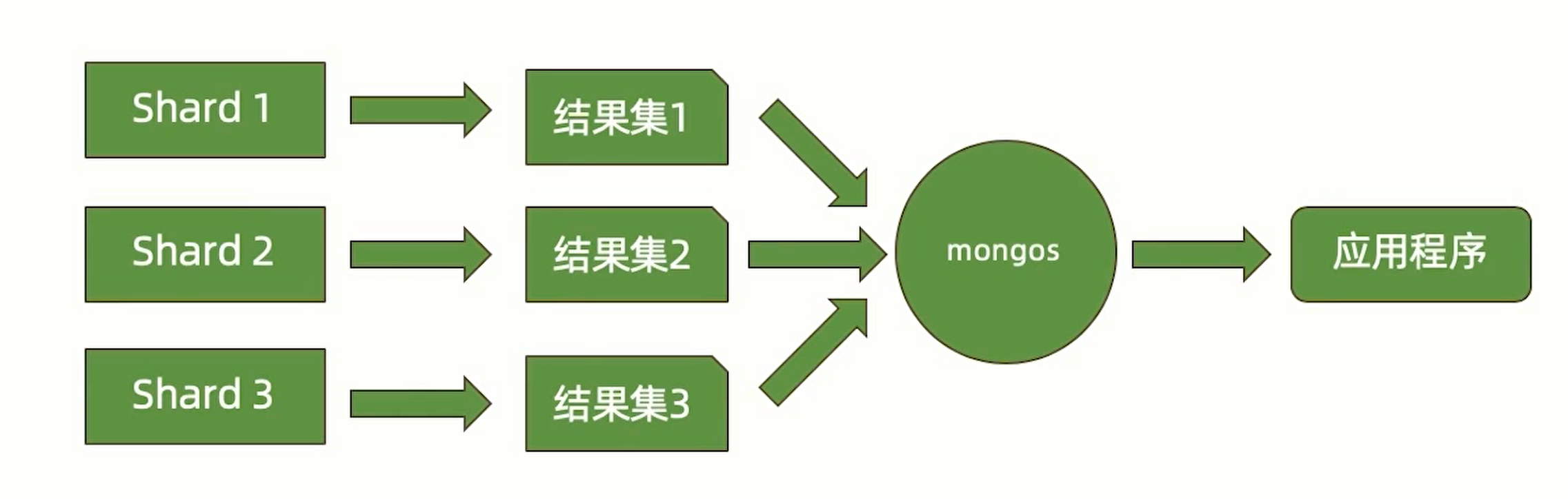
分片结果合并
- 避免在 MongoDB 中进行排序操作,减少数据库查询时间
- 尽可能使用带片键的查询条件,明确查询哪个分片,而不是都查一遍
网络传输
- 网络延迟
- 集群间开启 TLS/SSL 也影响传输性能
性能诊断
mongostat
统计同时发生了哪些操作,需要重点关注以下字段:
dirty: 内存更新了,但是没有持久化的数据,占比多少。低于 5% 时正常,超过 5% MongoDB 会加速写入, 超过 20% 时会阻塞新请求 ,全力写入磁盘。used: 分配给 MongoDB 的内存占用了多少。低于 80% 时正常,超过 80% MongoDB 会加速清理内存, 超过 95% 时会阻塞新请求 ,全力清理内存空间。qrw/arw: 排队的请求。conn: 连接数。
mongotop
了解集合压力状态的工具。
可以查询每个集合的 总时间 / 读时间 / 写时间。
mongod 日志
mongod 日志会记录执行超过 100ms 的查询以及 查询计划 。
mtools
开源 的 Python 工具,通过 pip install mtools 安装,常见命令如下:
mplotqueries ${mongod 日志文件}: 将所有慢查询通过图表可视化展示。mloginfo --queries ${mongod 日志文件}: 总结所有慢查询的模式和出现次数、消耗时间。
常见数据库集群设计方案
两地三中心集群设计
容灾级别
| 等级 | 灾难恢复策略 | RPO(恢复点目标) | RTO(恢复时间目标) | 实现方式与说明 |
|---|---|---|---|---|
| L0 | 无备源中心 | 24小时 | 4小时 | 仅本地数据备份,无灾难恢复能力 |
| L1 | 本地备份+异地保存 | 24小时 | 8小时 | 本地备份关键数据后送异地保存,需按预定程序恢复系统和数据 |
| L2 | 双中心主备模式 | 秒级 | 数分钟到半小时 | 异地建立热备份点,通过网络备份数据;灾难时备份站点接替主站点业务 |
| L3 | 双中心双活 | 秒级 | 秒级 | 两地建立相互备份的数据中心,任一中心故障时另一中心接管工作 |
| L4 | 双中心双活+异地热备(两地三中心) | 秒级 | 分钟级 | 同城双活中心+异地热备,当同城两中心同时不可用时快速切换至异地中心 |
常规两地三中心方案
网络层设计
DNS 服务器需要使用 GSLB 全局负载均衡(带 DNS 功能以及健康检查功能),在中心失活后 GSLB 自动切换为另一个中心。
应用层设计
- 使用负载均衡、虚拟 IP
- 使用同一个 Session
- 使用同一套设计
数据库设计
主要考虑跨中心同步问题
- DBMS 采用基于日志的同步方案
- 文件系统采用基于存储镜像的同步方案
MongoDB 两地三中心方案
三中心即为:同城双中心 + 异地中心
同城双中心都需要有双节点,异地中心单节点,也就是至少 5 节点。
主数据中心优先级最高,其次是同城备用中心,再次是跨城中心。
writeConcern 需要使用 majority 。
同城双中心需要使用低延迟专线,让数据同步时延降低,避免丢失数据。
完整的搭建步骤如下:
- 配置域名解析
- 安装 MongoDB
- 配置复制集
- 配置优先级
// 获取复制集配置
cfg = rs.conf()
// 修改第一个节点的优先级,默认为 1
cfg.members[0].priority = 10
// 让复制集更新配置信息
rs.reconfig(cfg)全球多写集群( global cluster )
业务需求:跨国企业跨地区读写时延高,时延接近秒级
解决方案如下:
使用多个分片集群,每个分片集群中,本地中心存在两台复制集节点,异地中心各有一台复制集节点。
本地数据读写都在本地中心,异地数据只能读,写需要通过异地数据中心才能写。
完整的搭建步骤如下:
- 针对要分片的数据集合,增加区域区分字段,只要能区分数据即可
- 给集群的每个分片加上区域标签
- 给每个区域指定属于这个区域的分片块范围
// 给分片 shard0 打标签
sh.addShardTag('shard0', 'Asia')
// 给分片指定数据范围
sh.addTagRange(
// 数据库.集合
'crm.orders',
// 分片的范围
{ locationCode: 'CN', order_id: 'min' },
{ locationCode: 'CN', order_id: 'max' },
// 给数据添加哪个标签
'Asia'
)通过 tag 可以帮助 MongoS 快速选择分片,减少跨中心读写。
上线准备
上线前
- 性能测试: 压测各项指标,比如 CURD 数、连接数等,设置好监控范围、调整硬件资源
- 环境检查: MongoDB 提供了一套上线前的环境检查 checklist ,可以按照上述内容进行检查
上线后
- 性能监控
- 定期巡检
版本升级
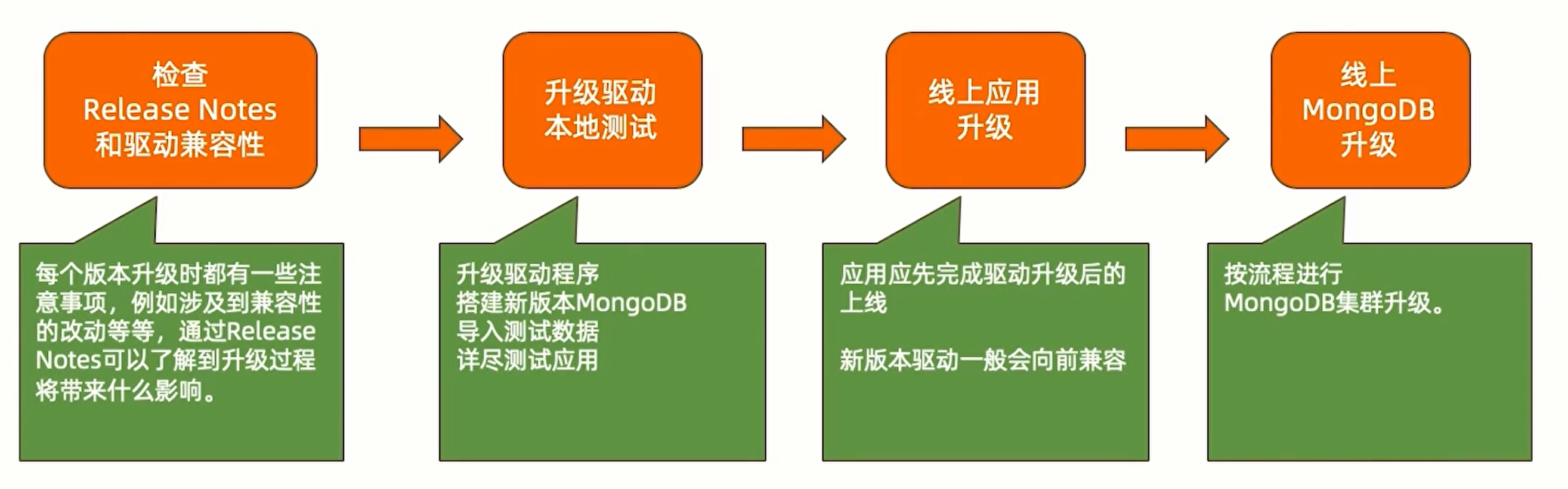
单机升级
单机升级完整升级流程如下:
复制集升级
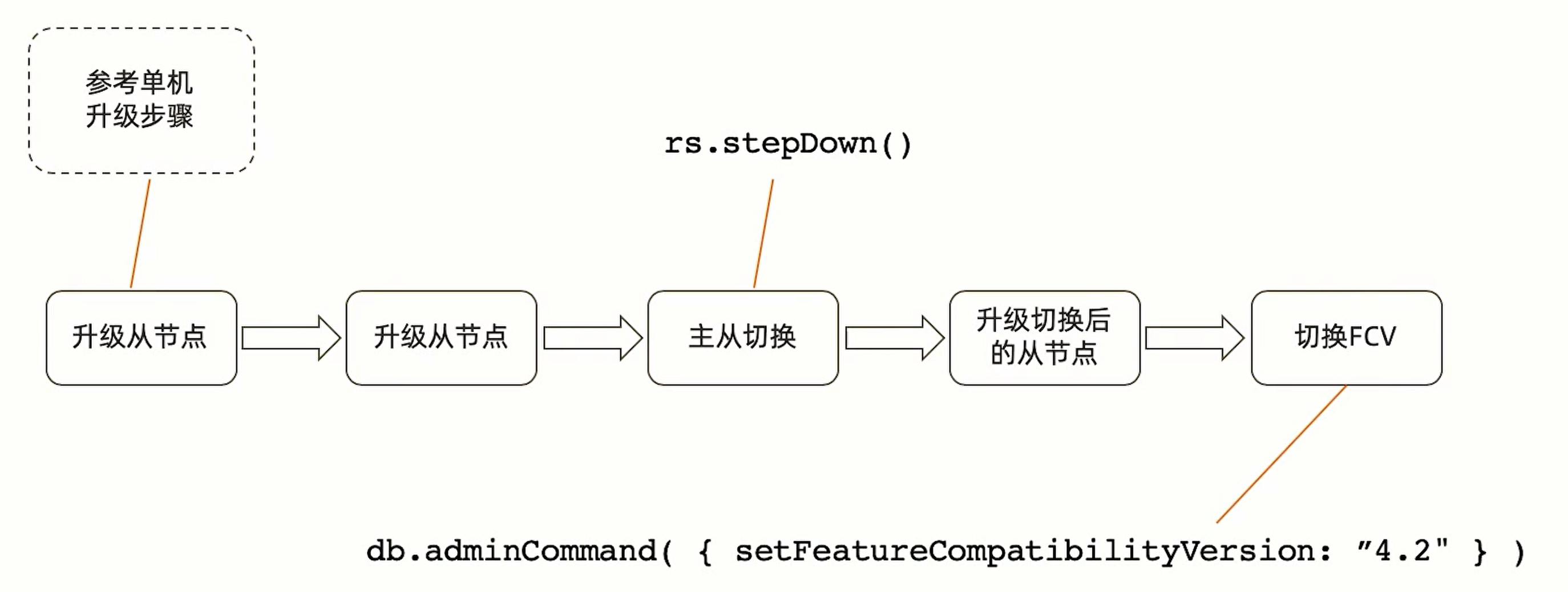
复制集升级一般是逐个节点升级,升级中的节点可以视为宕机,但是复制集还能继续工作,参考升级步骤如下:
降级
如果升级无论因何种原因失败,则需要降级到原有旧版本。在降级过程中:
- 滚动降级过程中集群可以保持在线,仅在切换节点时会产生一定的不可写时间
- 降级前应先去除已经用到的新版本特性。例如用到了 NumberDecimal 则应把所有使用 NumberDecimal 的文档先去除该字段
- 通过设置 FCV ( Feature CompatibilityVersion ) 可以在功能上降到与l旧版本兼容
- FCV 设置完成后再滚动替换为旧版本