本文目录
[[toc]]
常见目录
/: 根目录/root: root 用户的 Home/home/${username}: 普通用户的 Home/etc: 配置文件目录/bin: 命令目录/sbin: 管理命令目录/usr/bin//usr/sbin: 系统预装的其他命令
常用命令
部分常用命令
# 修改主机名
hostnamectl set-hostname 主机名
# 清空文件内容,并将 'content' 写入到 file 中
echo "content" > file
# 将 /dev/sr0 的磁盘制作成镜像,放到 /data/xxx.iso
dd if=/dev/sr0 of=/data/xxx.iso
# 将 /dev/sr0 的磁盘挂载到 /mnt/cd
mount /dev/sr0 /mnt/cd
# 查看 CPU 信息
lscpu
# 创建文件 outFile ,内容为 inFile 读取 4M 内容,操作重复 10 次,并且大小为 40M
dd if="${inFile}" bs=4M count=10 of="${outFile}"
# 创建空洞文件 outFile ,申请 20 * 4M 的空白空间再从 inFile 读取 4M 内容,操作重复 10 次,最终文件大小为 120M ,实际内容 40M
dd if="${inFile}" bs=4M count=10 seek=20 of="${outFile}"
# 以 code 1 返回
exit 1
# 如果上面的代码有错误, exit 返回最后一个错误码
# 如果没有错误,返回 0
exit
# 统计命令运行时间
time ls
# 遍历 1-100 ,写入 lines.txt 文件
seq 1 100 > lines.txt
# 输出文件内容,每行内容前面追加行号
cat -n lines.txt
# 查看当前登录的用户是谁
whoami查看命令帮助信息
man
使用 man 可以查看命令的帮助信息,分为 9 种类型:
- 可执行程序或命令
- 系统调用(由内核提供的函数)
- 库函数调用(程序库中的函数)
- 特殊文件(通常位于 /dev 目录下)
- 文件格式和约定,例如 /etc/passwd
- 游戏
- 杂项(包括宏包和约定),例如 man(7), groff(7)
- 系统管理命令(通常仅限 root 用户使用)
- 内核例程,已废弃
可以使用 man ${command} 获取命令帮助,如果出现重名的时候,可以通过数字指定获取的是什么帮助,比如 man 5 passwd 跟 man 1 passwd 就是不同的。
默认情况下,查询的都是 1 的类型
如果不确定查询什么类型的话,可以用 man -a ${command} 查询 1-9 所有同名的帮助信息。
type
如果希望查询,执行的内容属于什么,比如别名、函数、命令、可执行程序等等,可以使用 type ${command} 查看
help
如果是内部命令 ( shell 执行器自带的命令 ) ,可以使用 help ${command} 查询帮助信息,比如 help cd
如果是外部命令 ( 非内部命令 ) ,可以使用 ${command} --help 查询帮助信息,比如 ls --info
info
info 可以查看比 help 更详细的文档,一般作为 help 的补充,比如 info ls
ls
ls -a: 查看全部,包括隐藏文件ls -l: 展示详细信息,统计文件大小时,仅统计文件内容大小ls -r: 逆序展示ls -t: 按照时间排序ls -R: 递归展示所有文件ls -h: 将文件大小格式化展示
cd
cd -: 返回上次访问的目录,类似浏览器的回退cd ~: 返回当前用户的 Homecd /etc: 进入绝对路径cd etc: 进入相对路径
mv / cp
可以使用通配符 ? 与 *:
?: 匹配一个任意字符*: 匹配任意个任意字符
查看文本命令
cat
cat: 在终端打印文件信息
head
head 查看文件开头,默认将前 10 行打印到终端上,可以通过 head -${line} ${file} 指定打印前几行,比如 head -2 ~/.zsh_history
tail
tail 查看文件结尾,默认将后 10 行打印到终端上,可以通过 tail -${line} ${file} 指定打印前几行,比如 tail -2 ~/.zsh_history
tail -f: 文件更新后,同步展示更新,此时会进行交互阻塞,需要通过 ctrl c 终止,查看日志文件时必备。
wc
wc 可以统计文件内容信息
wc -l ${file}: 展示文件行数wc -c ${file}: 统计字节数wc -m ${file}: 统计字符数wc -L ${file}: 最长的那一行有多长wc -w ${file}: 统计文件内有多少单词
more / less
more可以对文件分页展示,通过空格翻页,只能一页一页翻less可以对文件分行展示,类似vim的状态,可以用方向键、 PageUp 、 PageDown 控制
tar
tar 可以打包、解包、压缩、解压文件
打包、压缩
tar c: 打包文件,将文件合并tar f: 指定操作类型为文件tar v: 查看操作过程
一般 cf 是一起使用的,也就是 tar cf ${打包后的文件名} ${需要打包的目录} ,文件名一般以 .tar 结尾,表示通过 tar 打包
但是这么打包,是不会对文件进行压缩的,为了方便传输,一般还需要通过 gzip 、 bzip2 压缩, tar 内部已经集成了压缩能力,可以通过 z 声明需要使用 gzip 压缩, j 声明使用 bzip2 压缩,也就是 tar czf ${打包后的文件名} ${需要打包的目录} 或者 tar cjf ${打包后的文件名} ${需要打包的目录}
为了区分压缩与未压缩,一般压缩文件使用 .tar.gz 表示使用 gzip 压缩,使用 .tar.bz2 表示使用 bzip2 压缩。
由于双扩展名比较长,一般使用 .tgz 表示 .tar.gz 、 .tbz2 表示 .tar.bz2 。
bzip2 压缩率更高,但是处理时间更长,按需选择即可。
解压、解包
tar x: 解包文件,将包还原为文件 / 目录tar f: 指定操作类型为文件tar z: 使用gzip解压tar j: 使用bz2解压
vi
vim 是 vi 扩展版本,向上兼容, vi 存在四种模式:
- 正常模式
- 插入模式
- 命令模式
- 可视模式
正常模式
i: 进入插入模式,光标在当前位置I: 进入插入模式,光标在当前行头部a: 进入插入模式,光标在当前位置的下一个位置A: 进入插入模式,光标在当前行尾部o: 进入插入模式,在下方插入一行,并移动光标到新行O: 进入插入模式,在上方插入一行,并移动光标到新行y: 复制yy: 复制当前行${line}yy: 复制${line}行内容y$: 复制从当前位置到结尾的所有内容
d: 剪切dd: 剪切当前行d$: 剪切从当前位置到当前行结尾的所有内容
p: 粘贴u: 撤销操作ctrl r: 撤销撤销操作x: 删除当前字符r${char}: 当前字符替换为指定字符移动光标
h/j/k/l: 左 / 下 / 上 / 右 移动光标${line}shift g: 移动到低${line}行开头gg: 到达第一行G: 到达最后一行^: 到达行开头$: 到达行末尾
:: 进入命令模式v: 进入字符可视模式V: 进入行可视模式ctrl v: 进入块可视模式
命令模式
:w ${file}: 另存为文件,省略${file}则是保存:q: 退出vi:q!: 退出并且不保存:!${shell}: 执行${shell}命令,临时退出vi,命令回显退出后回到vi:/${string}: 查找匹配内容,n会查找下一个,ctrl n查找上一个- 文本替换
:s/${old}/${new}: 文本替换,将旧值替换为新值,只会替换当前行的内容,如果需要全部替换,需要使用:s/${old}/${new}/g:%s/${old}/${new}: 文本替换,将旧值替换为新值,替换范围为整个文件,如果需要全部替换,需要使用:%s/${old}/${new}/g:${startLine},${endLine}s/${old}/${new}: 文本替换,将旧值替换为新值,替换范围为${startLine}到${endLine},如果需要全部替换,需要使用:${startLine},${endLine}s/${old}/${new}/g
:set: 临时修改设置:set nu: 设置行号:set nonu: 取消行号:set hlsearch: 搜索高亮:set nohlsearch: 取消搜索高亮
可视模式
v: 字符可视,从当前位置,按照移动选择连续字符V: 行可视,从当前位置,按照移动逐个选择行ctrl v: 块可视,从当前位置,按照移动逐个选择块,块即为矩形区域
选中后,通过 ctrl i + 两次 esc 可以快速为块中每一行都添加指定字符
权限管理
用户权限
用户管理
useradd ${username}: 新增用户,会同步创建 Home 目录,并记录到/etc/passwd、/etc/shadow,未指定组时,创建用户同名组useradd -g ${group} ${username}: 新增用户,并放到指定用户组,而不是创建新同名组
id ${username}: 确认是否存在指定用户passwd ${username}: 修改用户密码,如果没有输入${username},则修改当前用户密码userdel ${username}: 删除用户,不删除用户数据,保留 Home ,并 Home 会被设置为无主权限,只能由root访问userdel -r ${username}: 彻底删除用户以及用户所有数据,包括 Home
usermod [options] ${username}: 修改用户属性usermod -d /home/xxx ${username}: 修改用户的 Home 目录为/home/xxxusermod -g ${group} ${username}: 将用户放到指定用户组中
chage: 修改密码过期信息,比如密码有效期、修改密码的间隔时间等等
用户组管理
groupadd ${group}: 新增用户组groupdel ${group}: 删除用户组
用户切换
su: 切换用户su ${username}: 切换用户身份,但保留在当前终端su - ${username}: 切换用户身份,会登录到对应的用户终端,并切换到对应用户的 Home
sudo: 使用其他用户身份执行命令,需要进行对应用户的密码验证visudo: 设置能够使用sudo的用户(组),以及能够执行哪些权限,需要使用当前用户命令进行验证
用户配置文件
vi /etc/passwd 打开用户配置文件
root:x:0:0:root:/root:/bin/bashroot: 用户名x: 是否需要密码验证,x为需要0: 用户uid。 Linux 是根据uid标识用户的,如果将普通用户的uid修改为0,普通用户也会变成root用户,普通用户一般从1000开始自增0: 用户所在的用户组 id 。root: 注释信息/root: 用户的 Home 目录/bin/bash: 用户登录后打开的命令解释器
用户密码配置文件
vi /etc/shadow 打开用户密码配置文件
he110:$6$TmibBbIpSjJs1Q8V$gMyULqUA0J65TKuHCSzR6123456/5Q2v.J/wAwFDnc7W08atsoe/6tx0GmYNKar3R/Q5fhAqRAg9CS3ZiwPWi.:19935:0:99999:7:::he110: 用户名$6$TmibBbIpSjJs1Q8V$gMyULqUA0J65TKuHCSzR6123456/5Q2v.J/wAwFDnc7W08atsoe/6tx0GmYNKar3R/Q5fhAqRAg9CS3ZiwPWi.: 用户加密过的密码,哪怕相同密码,加密后也不同。
用户组配置文件
vi /etc/group 打开用户组配置文件
test:x:0:roottest: 组名x: 是否需要密码验证x为需要0: 组 IDroot: 当前组属于哪个组,root指属于root组
文件权限
查看文件权限
通过 ls -l 可以查看文件权限
drwxr-xr-x 3 username groupname filesize createdTime filenamedrwxr-xr-x 即为访问权限信息
d: 文件类型-: 普通文件d: 目录文件b: 块特殊文件,也就是设备c: 字符特殊文件l: 符号链接f: 命名管道s: 套接字文件
r: 是否有读权限,没有为-, 数字表示为4w: 是否写入权限,没有为-, 数字表示为2x: 是否执行权限,没有为-, 数字表示为1
rwx 为一组,重复三次
- 第 1 组
rwx为 文件所属用户username的操作权限 - 第 2 组
rwx为 文件所属用户组groupname的操作权限 - 第 3 组
rwx为 其他用户 的操作权限
对于目录来说
x: 进入目录r: 显示目录文件名,必须先有x才行w: 修改目录内的文件名,必须先有x才行
修改文件权限
chmod: 修改文件、目录权限chmod +x ${file}: 为文件所属用户、所属用户组、其他用户都添加可执行权限chmod u+x ${file}: 为 文件所属用户 添加 可执行权限chmod g-x ${file}: 为 文件所属用户组 移除 可执行权限chmod o=r ${file}: 为 其他用户 设置 为 可读权限chmod a=rw ${file}: 为文件所属用户、所属用户组、其他用户都 设置 为 可读写权限chomd 700 ${file}: 只有所属用户可以读取、写入、执行文件, 三位数字代表三组rwx的值之和umask: 一般为022,默认权限为777 - umask,所以默认权限就是644了
chown: 修改所属用户、所属用户组chown ${username} ${file}: 修改${file}文件为${username}所属chown :${groupname} ${file}: 修改${file}文件为${groupname}所属chown ${username}:${groupname} ${file}: 同时修改${file}文件所属用户名与用户组
chgrp: 单独修改所属用户组chgrp ${groupname} ${file}: 修改${file}文件为${groupname}所属
当文件所属用户与文件所属用户组,权限冲突时,优先匹配所属用户,再匹配所属用户组,最后匹配其他用户。
比如 对于
group1的user1没有任何权限,但是group1有读写权限。
user1将无法读写文件,group1中的其他用户可以读写文件。
特殊权限
SUID: 用于二进制可执行文件,执行命令的时候,自动获取文件所属用户的权限,不需要密码,比如 修改文件命令 (/usr/bin/passwd)chmod 4755 ${file}: 第一个 4 即为设置SUID权限
SGID: 用于目录,在该目录下创建新文件与目录,权限自动修改为该目录所属用户组,用于文件共享chmod 2755 ${file}: 第一个 2 即为设置SUID权限
SBIT: 用于目录,该目录下新建的文件和目录,仅 root 与自己可以删除chmod 1755 ${file}: 第一个 1 即为设置SUID权限
网络管理
网络状态查看
老版本 Linux 使用 net-tools ,新版本使用的是 iproute
net-tools 包括
ifconfig:lo: 本地环回eth1: 板载网卡ens33: PCI-E 网卡,老版本 Linux 没有enp0s3: 无法获取物理信息的 PCI-E 网卡,老版本 Linux 没有eth0: 以上都不匹配使用eth0,指第一块网卡,多个网卡会递增。
route: 查看网关,会将 IP 解析为主机名,比较慢,推荐使用route -nnetstat: 查看当前的网络监听信息。
iproute 包括
ipss
ipconfig
回显中常用参数含义如下:
inet: 网络 IPnetmask: 网络掩码ether: 网卡 MACRX packets: 接收了多少数据包RX errors: 接收了多少错误数据包TX packets: 发送了多少数据包TX errors: 发送了多少错误数据包
修改网卡名称
vim /etc/default/grub 编辑网卡配置可以批量修改网卡名称
# 传递给 Linux 内核的参数
GRUB_CMDLINE_LINUX="rd.lvm.lv=centos/root rd.lvm.lv=centos/swap rhgb quiet"
# 修改为以下配置,可以让网卡从 eth0 自增,不区分网卡
GRUB_CMDLINE_LINUX="rd.lvm.lv=centos/root rd.lvm.lv=centos/swap rhgb quiet biosdevname=0 net.ifnames=0"让 grub 配置生效可以使用 grub2-mkconfig -o /boot/grub2/grub.cfg
然后重启即可
网关配置
ifconfig ${eth} ${ip} [netmask ${mask}]: 设置网卡 IP 地址、掩码等ifup ${eth}: 启用网卡ifdown ${eth}: 禁用网卡route add default gw ${gateway}: 添加默认网关,add修改为del即为删除route add -host ${IP} gw ${gateway}: 添加明细路由,访问 IP 时,使用指定的 gatewayroute add -net ${网段} netmask ${mask} gw ${gateway}: 访问网段时,使用指定的 gatewayip addr ls: 等同于ifconfigip link set dev ${eth} up: 等同于ifup ${eth}ip link set dev ${eth} down: 等同于ifdown ${eth}ip addr add 1.1.1.1/24 dev ${eth}: 等同于ifconfig ${eth} 1.1.1.1 netmask 255.255.255.0ip route add 1.1.1.1/24 via 192.168.0.1: 等同于route add -net 1.1.1.1 netmask 255.255.255.0 gw 192.168.0.1
网络排障
ping: 查看主机联通状态traceroute: 跟踪每一跳路由,可以看数据在哪里丢失,如果中间主机不支持追踪,会展示*traceroute -w 1 www.baidu.com: 超时时间为 1s ,跟踪访问百度
mtr: 集成了ping与traceroute,展示内容更丰富nslookup: 查看 dns 解析telnet: 检查端口是否联通,比如telnet www.baidu.com 80tcpdump: 抓包工具,比如tcp -i any -n host 1.1.1.1 and port 80:-i: 指定抓包的网卡-n: 会将域名解析为 IP 地址host: 指定目的 IPport: 指定目的端口and: 查询条件联合,如果单条件不需要and
netstat: 查看端口监听状态,比如netstat -ntpl-n: 会将域名解析为 IP 地址-t: 查看 TCP 协议-p: 打印信息带上进程名-l:state为LISTEN
ss:netstat替代,例如ss -ntpl-n: 会将域名解析为 IP 地址-t: 查看 TCP 协议-p: 打印信息带上进程名-l:state为LISTEN
网络框架
从 Linux 内核 2.4 版本开始,内核引入了一套通用的过滤框架 —— Netfilter ,允许外界对网络数据包在内核协议栈流转过程中进行代码干预。
Linux 系统中的各类网络功能,如地址转换、封包处理、地址伪装、协议连接跟踪、数据包过滤、透明代理、带宽限速和访问控制等,都是基于 Netfilter 提供的代码拦截机制实现的。可以说, Netfilter 是整个 Linux 网络系统最重要(没有之一)的基石。
Netfilter 围绕网络协议栈(主要在网络层)埋下了 5 个钩子(也称 hook ),用来干预 Linux 网络通信。
内核中的其他模块(如 iptables 、 IPVS 等)向这些钩子注册回调函数。当数据包进入内核网络协议栈并经过这些钩子时,注册的回调函数自动触发,从而对数据包进行相应的干预和处理。
这 5 个钩子的名称与含义如下:
PREROUTING: 只要数据包从设备(如网卡)进入协议栈,就会触发该钩子。当我们需要修改数据包的Destination IP时,会使用到该钩子,即PREROUTING钩子主要用于目标网络地址转换(DNAT,Destination NAT)。FORWARD: 顾名思义,指转发数据包。前面的PREROUTING钩子并未经过IP路由,不管数据包是不是发往本机的,全部照单全收。如果发现数据包不是发往本机,则会触发FORWARD钩子进行处理。此时,本机就相当于一个路由器,作为网络数据包的中转站,FORWARD钩子的作用就是处理这些被转发的数据包,以此来保护其背后真正的“后端”机器。INPUT: 如果发现数据包是发往本机的,则会触发本钩子。INPUT钩子一般用来加工发往本机的数据包,当然也可以做数据过滤,保护本机的安全。OUTPUT: 数据包送达到应用层处理后,会把结果送回请求端,在经过IP路由之前,会触发该钩子。OUTPUT钩子 一般用于加工本地进程输出的数据包,同时也可以限制本机的访问权限。比如,将发往www.example.org的数据包都丢弃掉。POSTROUTING: 数据包出协议栈之前,都会触发该钩子,无论这个数据包是转发的,还是经过本机进程处理过的。POSTROUTING钩子 一般用于源网络地址转换(SNAT,Source NAT)。

处理网络包流程
- 外部数据包到达主机时,首先由网卡
eth0接收。 - 网卡通过
DMA( Direct Memory Access, 直接内存访问)技术,将数据包拷贝到内核中的RingBuffer(环形缓冲区)等待CPU处理。RingBuffer是一种首尾相接的环形数据结构,它作为缓冲区,缓解网卡接收数据的速度快于CPU处理数据的速度问题。 - 接着,网卡产生
IRQ( Interrupt Request, 硬件中断),通知内核有新的数据包到达。 - 内核调用中断处理函数,标记新数据到达。接着,唤醒
ksoftirqd内核线程,执行软中断( SoftIRQ )处理。 - 软中断处理中,内核调用网卡驱动的
NAPI( New API )poll接口,从RingBuffer中提取数据包,并转换为skb( Socket Buffer )格式。skb网络子系统中用于描述网络数据包的核心数据结构。数据包的发送、接收还是转发,内核都会通过skb来处理。 skb被传递到内核协议栈,在多个网络层次间处理:- 网络层( L3 Network layer ):根据主机中的路由表,判断数据包路由到哪一个网络接口( Network Interface )。这里的网络接口可能是稍后介绍的虚拟设备,也可能是物理网卡
eth0接口。 - 传输层( L4 Transport layer ):处理网络地址转换( NAT )、连接跟踪( conntrack )等。
- 网络层( L3 Network layer ):根据主机中的路由表,判断数据包路由到哪一个网络接口( Network Interface )。这里的网络接口可能是稍后介绍的虚拟设备,也可能是物理网卡
- 内核协议栈处理完成后,数据包被传递到
socket接收缓冲区。应用程序利用系统调用(如Socket API)从缓冲区读取数据。至此,整个收包过程结束。
传输成本问题
分析 Linux 系统处理网络数据包的过程,我们注意到潜在问题:数据包的处理流程过于冗长。
处理流程涉及到多个网络层协议栈(如数据链路层、网络层、传输层和应用层),网络层协议栈之间需要封包/解包,还有频繁的上下文切换( Context Switch ),都让 Linux 内核的瓶颈不可忽视。
对于设计网络密集型系统,优化内核参数是不可或缺的一环。
除了想办法优化内核参数,另外一批人抱着它不行就绕开它想法,提出了一种“内核旁路“( Kernel bypass )思想的技术方案。其中, DPDK 和 XDP 是主机内“内核旁路”思想的代表技术, RDMA 是主机之间“内核旁路”思想的代表技术。

DPDK ( Data Plane Development Kit, 数据平面开发套件)
- 传统内核网络 (图左侧): 网络数据包自网络接口卡(
NIC)出发,经过驱动程序,内核协议栈,最后通过Socket接口传递至业务逻辑。 DPDK加速网络 (图右侧): 在该方案中,网络数据包利用 用户空间I/O(UIO)技术,直接绕过内核协议栈,从网卡转移到DPDK基础库,然后传递至业务逻辑。也就是说DPDK绕过了Linux内核协议栈对数据包的处理过程,在用户空间直接对数据包进行收发与处理。
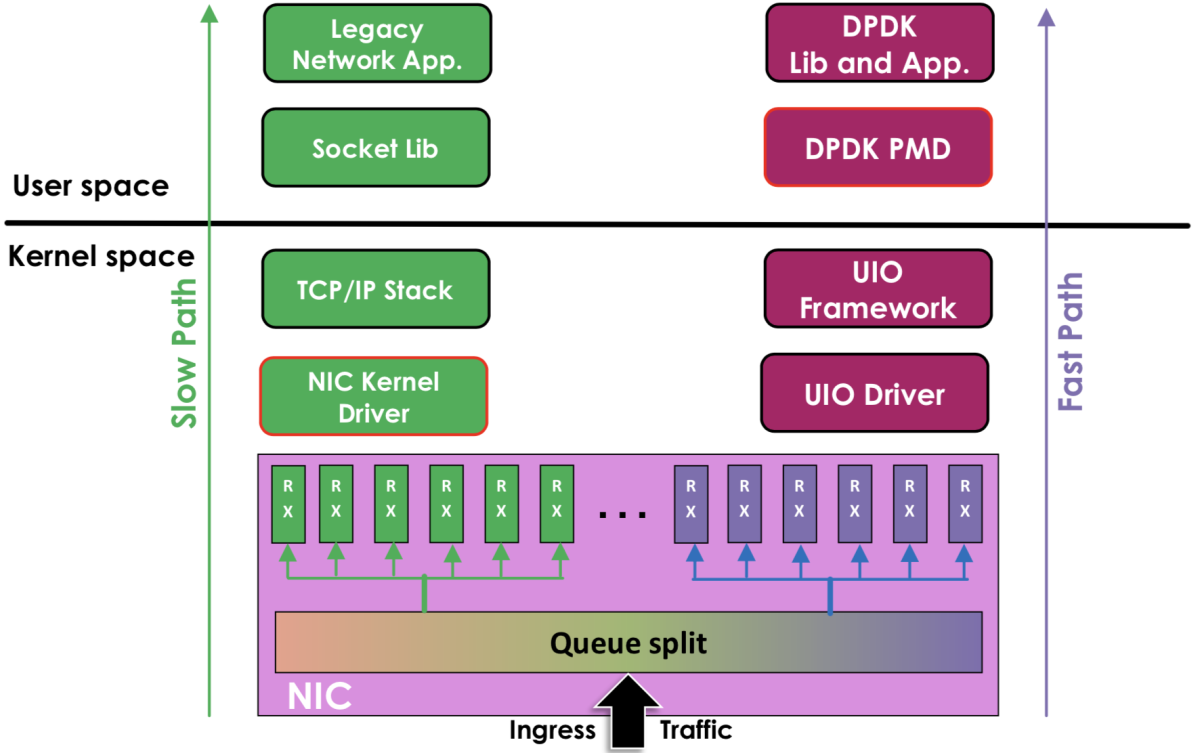
爱奇艺开源的
DPVS是DPDK技术在负载均衡领域的成功应用。从每秒转发数据包数量( Packet Per Second, PPS )指标来看,DPVS的性能表现比LVS高出 300%。
eBPF 和 快速数据路径 XDP ( eXpress Data Path, 快速数据路径)
DPDK 技术完全绕过内核,直接将数据包透传至用户空间处理。 XDP 正好相反,它在内核空间根据用户的逻辑处理数据包。
在内核执行用户逻辑的关键在于 BPF ( Berkeley Packet Filter ,伯克利包过滤器)技术 —— 一种允许在内核空间运行经过安全验证的代码的机制。 Linux 内核 2.5 版本起, Linux 系统就开始支持 BPF 技术了,但早期的 BPF 主要用于网络数据包的捕获和过滤。到了 Linux 内核 3.18 版本,开发者推出了一套全新的 BPF 架构,也就是我们今天所说的 eBPF ( Extended Berkeley Packet Filter )。与早期的 BPF 相比, eBPF 的功能不再局限于网络分析,它几乎能访问所有 Linux 内核关联的资源,逐渐发展成一个多功能的通用执行引擎。
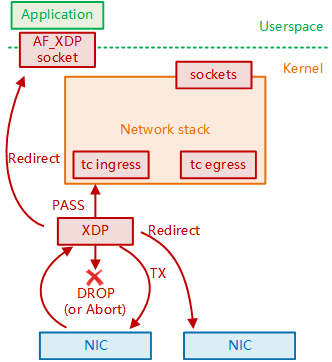
XDP 本质是 Linux 内核在网络路径上埋下的钩子,该钩子位于网卡驱动层内,数据包进入网络协议栈之前。如果 XDP 钩子挂载了 eBPF 程序,就能在 Linux 系统收包早期阶段介入处理,避免数据包“循规蹈矩”的进入内核,带来的额外开销。
XDP 执行完 eBPF 逻辑之后,用“返回码”作为输出,它代表对数据包应该做什么样的最终裁决。 XDP 支持的 5 种返回码名称及含义如下:
XDP_ABORTED: 表示XDP程序处理数据包时遇到错误或异常。XDP_DROP: 在网卡驱动层直接将该数据包丢掉,通常用于过滤无效或不需要的数据包,如实现DDoS防护时,丢弃恶意数据包。XDP_PASS: 数据包继续送往内核的网络协议栈,和传统的处理方式一致。这使得XDP可以在有需要的时候,继续使用传统的内核协议栈进行处理。XDP_TX: 数据包会被重新发送到入站的网络接口(通常是修改后的数据包)。这种操作可以用于实现数据包的快速转发、修改和回环测试(如用于负载均衡场景)。XDP_REDIRECT: 数据包重定向到其他的网卡或CPU,结合AF_XDP可以将数据包直接送往用户空间。
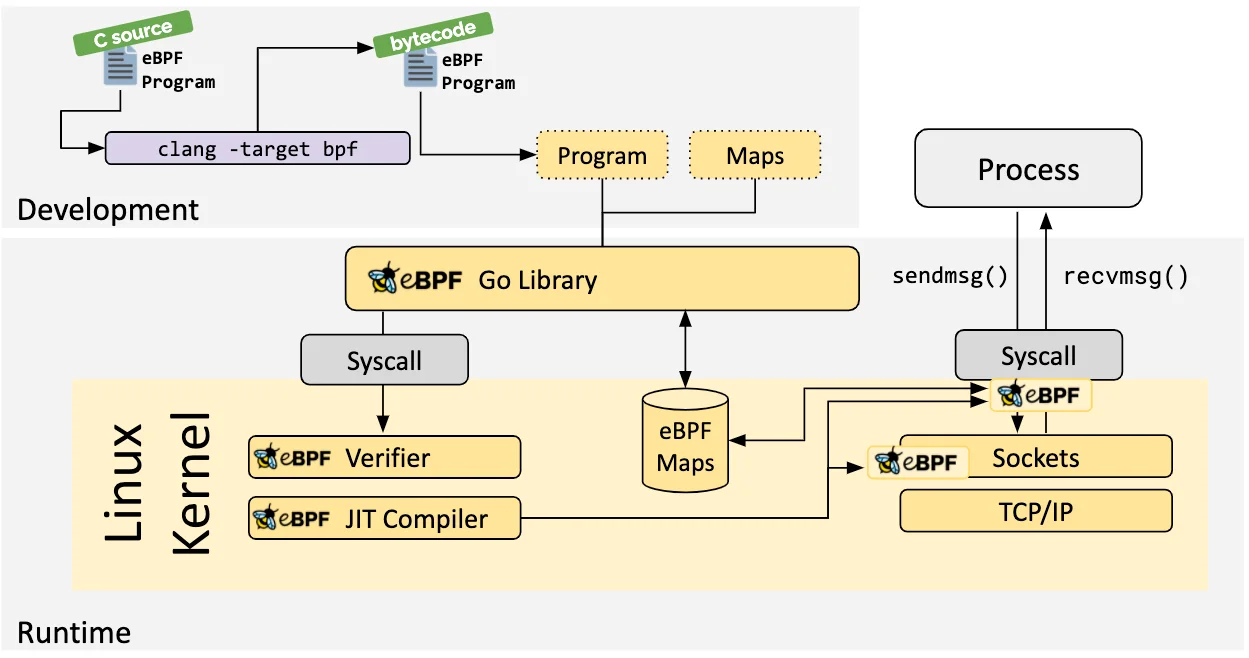
通过下面的步骤,进一步了解 eBPF 程序是如何被 Linux 内核加载、验证并执行:
- 编写的
eBPF程序,经过编译器,编译为eBPF字节码。 - 编译好的代码,会被
eBPF所对应的高级编程语言库程序加载,并由高级语言进行系统调用处理。目前eBPF支持Golang、Python、C/C++、Rust等。 - 通过系统调用陷入内核后,首先由内核
eBPF程序进行验证( verify ),这一步确保程序本身无误:不会崩溃,不会出现死循环,没有权限异常;然后编译为eBPF伪代码的程序再转换为具体的机器指令集,最终挂载到对应的钩子处(或称追踪点)。 - 内核在处理某个追踪点时,刚好有
eBPF程序,则触发事件,并由加载的eBPF程序处理
eBPF 能够在不修改内核源码的情况下,动态加载和执行用户定义的代码,在 Linux 内核的多个子系统,如网络、跟踪和 Linux 安全模块( LSM )中广泛应用。基于 eBPF 技术的开源项目也层出不穷,如 Facebook 的高性能网络负载均衡器 Katran 、内核跟踪调试工具 BCC 和 bpftrace ,以及 Isovalent 的容器网络方案 Cilium 等。
以 Cilium 为例,它在 eBPF 和 XDP 钩子(也有其他的钩子)基础上,实现了一套全新的 conntrack 和 NAT 机制。并以此为基础,构建出如 L3 / L4 负载均衡、网络策略、观测和安全认证等各类高级功能。
由于 Cilium 实现的底层网络功能现独立于 Netfilter ,因此它的连接追踪数据和 NAT 规则数据不会存储在 Linux 内核默认的 conntrack 表和 NAT 表中。常规的 Linux 命令 conntrack 、 netstat 、 ss 和 lsof 等,无法查看 NAT 规则和连接追踪数据。得使用 Cilium 提供的查询命令才行,例如:
cilium bpf nat list ## 列出 Cilium 中配置的 NAT 规则。
cilium bpf ct list global## 列出 Cilium 中的连接追踪条目RDMA ( Remote Direct Memory Access, 远程直接内存访问)
传统的以太网在网络延迟、吞吐量和 CPU 资源消耗方面存在先天不足。此背景下,广泛应用于高性能计算领域的 RDMA ( Remote Direct Memory Access ,远程直接内存访问)技术脱颖而出。
RDMA 设计灵感来源于 DMA (Direct Memory Access,直接内存访问),是一种允许主机之间直接访问彼此内存的技术。
DMA 技术中,无需 CPU 参与,主机内部的设备(如硬盘或网卡)能够直接与内存交换数据; RDMA 的工作原理如图所示,应用程序通过专用的接口(RDMA Verbs API)绕过主机操作系统和 TCP / IP 协议栈,达到了直接访问远程主机内存的效果。
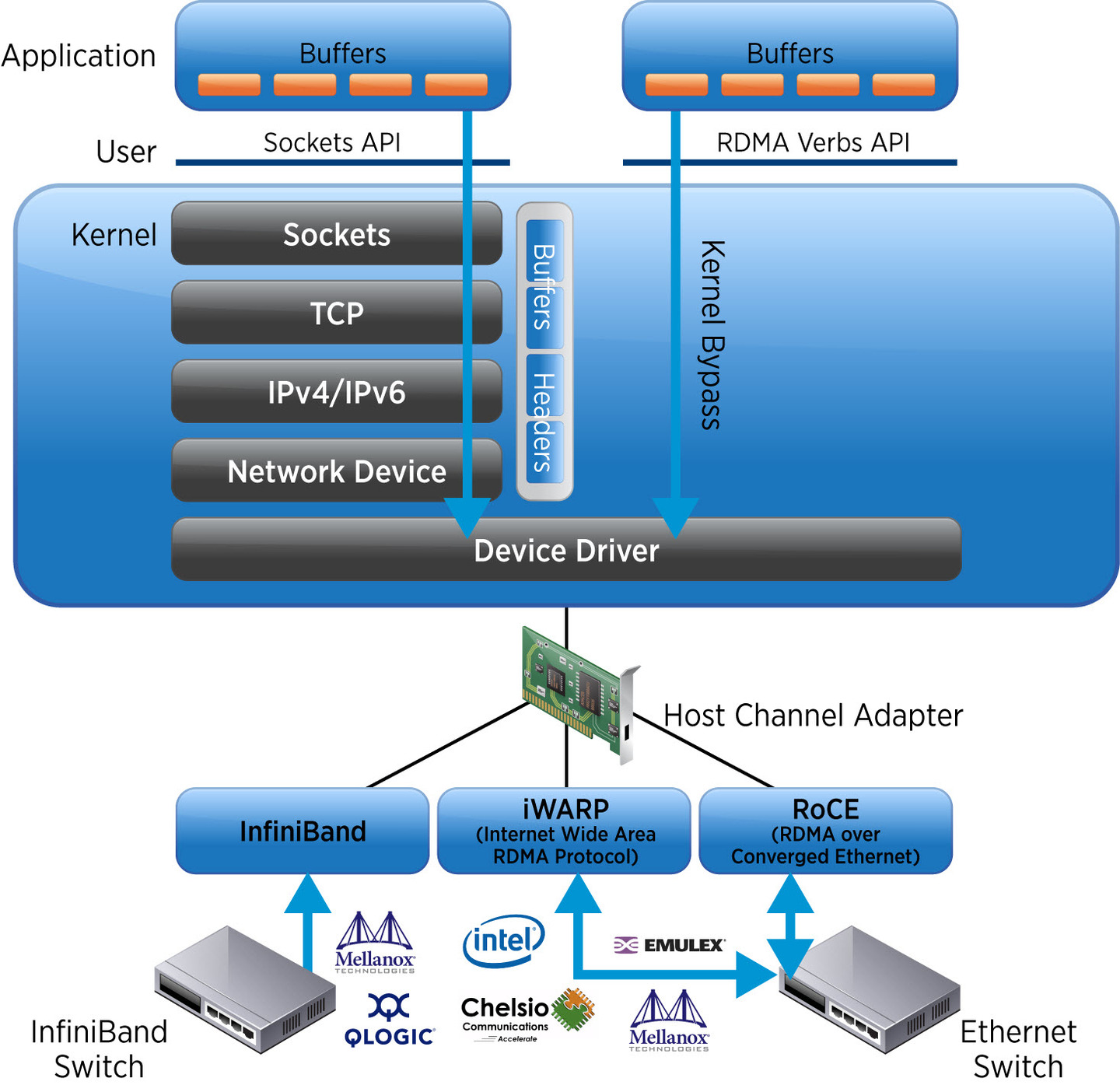
RDMA 网络的协议实现分为三类: Infiniband 、 iWARPRoCE ,它们的含义及区别如下:
Infiniband(无限带宽),是一种专门为RDMA而生的技术,由IBTA( InfiniBand Trade Association, InfiniBand 贸易协会)在 2000 年提出,因其极致的性能(能够实现小于 3 μs 时延和 400Gb/s 以上的网络吞吐),在高性能计算(HPC)领域中备受青睐。 但注意的是,构建Infiniband网络需要配置全套专用设备,如专用网卡、专用交换机和专用网线,限制了其普及性。其次,它的技术架构封闭,不兼容现有的以太网标准。这意味着,绝大多数通用数据中心都无法兼容Infiniband网络。尽管存在上述缺陷,但
Infiniband因其卓越的性能仍然是某些领域是首选。例如,全球流行的人工智能应用ChatGPT背后的分布式机器学习系统就是基于Infiniband网络构建的。iWRAP( Internet Wide Area RDMA Protocol, 互联网广域 RDMA 协议),这是一种将RDMA封装在TCP/IP协议内的技术。RDMA网络为了高性能而生,而TCP/IP协议为了可靠性而生,它的三次握手、拥塞控制等机制让iWRAP失去了绝大部分RDMA技术的优势。所以,先天设计缺陷让iWRAP逐渐被业界抛弃。为了降低
RDMA技术的使用成本,并使其应用于通用数据中心领域, 2010 年, IBTA 发布了RoCE(RDMA over Converged Ethernet, 融合以太网的远程直接内存访问)技术,将Infiniband的数据标准(IB Payload)“移植”到以太网。只需配备支持RoCE的专用网卡和标准以太网交换机,即可享受RDMA技术带来的高性能。RoCEv1基于二层以太网,局限于同一子网,无法跨子网通信。RoCEv2基于三层 IP 网络,支持跨子网通信。
RoCEv2 解决了 RoCEv1 无法跨子网的局限,凭借其低成本和兼容性优势, RoCE 技术开始广泛应用于分布式存储、并行计算等通用数据中心场景。根据云计算平台 Azure 公开的信息,至 2023 年,Azure 整个数据中心 70% 的流量已经是 RDMA 流量了
RDMA 网络对丢包极为敏感,任何数据包的丢失都可能导致大量重传,降低传输性能。 Infiniband 网络依靠专用设备来确保网络可靠性,而 RoCE 网络则基于标准以太网实现 RDMA ,这要求基础设施必须具备无损以太网功能,以避免丢包对性能造成严重影响。
目前,大多数数据中心使用
DCQCN(微软和 Mellanox 提出)或者HPCC(阿里巴巴提出)算法为RoCE网络提供可靠性保障。
软件包管理
包管理器
CentOS 、 RedHat 使用 yum 作为管理器,软件包格式为 rpm ,包格式为 ${软件名}-${版本号}.${系统版本}.${平台}.rpm
rpm 常见命令如下:
rpm -q ${software}: 查询是否安装了${software}rpm -qa | more: 查询安装了哪些软件包,并且分页展示rpm -i ${xxx.rpm}: 手动安装指定软件包, rpm 不能自动安装依赖包,需要手动处理缺失依赖rpm -e ${software}: 手动卸载指定软件包
yum 可以自动识别依赖,并自动下载依赖包,软件源配置存放在 /etc/yum.repos.d/CentOS-Base.repo 中
yum makecache: 更新源后使用,清空软件包缓存,重新下载源数据yum install ${software}: 安装${software}yum remove ${software}: 移除${software}yum list: 查看软件包yum grouplist: 查看软件包yum update [${software}]: 升级(指定)软件包
Ubuntu 、 Debian 使用 apt 作为管理器,软件包格式为 deb
dpkg 常见命令如下:
dpkg-query ${software}: 查询是否安装了${software}dpkg-query -l | more: 查询安装了哪些软件包,并且分页展示dpkg -i ${xxx.dpkg}: 手动安装指定软件包, rpm 不能自动安装依赖包,需要手动处理缺失依赖dpkg -r ${software}: 手动卸载指定软件包
编译安装
包管理器中的版本通常较低,需要使用最新版可以采用二进制安装或者编译安装,部分软件包也并没有提供包管理器安装方案,只能手动安装。
一般编译安装的过程如下:
# 声明版本号,避免重复输入
$version=1.15.8.1
# 下载源码
wget "https://openresty.org/download/openresty-${version}.tar.gz"
# 解压源码
tar -zxf "openresty-${version}.tar.gz"
# 进入解压后 源码目录
cd "openresty-${version}/"
# 按照运行环境进行配置,比如设置安装路径等等
./configure--prefix=/usr/local/openresty
# 编译源码为可执行程序 -j2 指使用 CPU 两个核心用于编译
# 在编译时可能出现各种问题,比如 gcc 库版本不匹配、依赖软件包未安装等,可以参考报错信息或者官方文档解决。
make -j2
# 安装软件包
makeinstall不同软件的安装方式有所差异,具体需要看软件提供的安装说明。
内核升级
# 查看内核版本
uname -r
# 升级内核版本
yum install "kernel-${version}"
# 更新软件包
yum update内核编译安装
# 安装编译依赖包
yum install gcc gcc-c++ make ncurses-devel openssl-devel elfutils-libelf-devel
# 下载需要在官方 https://www.kernel.org 手动下载
# 源码存放路径
$source='/usr/src/kernals'
# 解压内核
tar xvf linux-5.1.10.tar.xz -C $source
# 进入源码目录
cd "${source}/linux-5.1.10"
# === 以下配置方式任选其一 === #
# 通过菜单进行配置
make menuconfig
# 全选内核功能
make allyesconfig
# 最小内核
make allnoconfig
# 使用当前系统的内核编译配置
cp /boot/config-kernelversion.platform "${source}/linux-5.1.10/.config"
# === 配置完成 === #
# 编译配置的全部内容,使用 2 个 CPU 核心进行编译
make -j2 all
# 先安装内核支持的模块
make modules_install
# 再安装内核
make install
# 查询 Linux grub 配置,查找有几个内核程序
grep ^menu /boot/grub2/grub.cfg
# 设置默认选择第几个内核, 0 就是第一个,也就是更新的内核
grub2-set-default 0grub 配置文件存放在 /etc/default/grub
# 为 Linux 添加哪些配置, Linux 启动时,通过 e 可以看到下述参数被追加到 Linux 内核启动命令中
# - rhgb: 指在启动时使用图形界面
# - quiet: 指在启动时只输出必要信息
# - single: 遗忘密码时,可以直接跳过密码登录
# - rd.break:
GRUB_CMDLINE_LINUX="rd.lvm.lv=centos/root rd.lvm.lv=centos/swap rhgb quiet"忘记密码重置
忘记密码时,可以通过启动时按 e ,进入 Linux 引导程序,配置启动参数 ( linux16 开头的就是 )
追加 single 与 rd.break ( CentOS 7 及以上需要 ) ,通过 ctrl x 使用该参数启动
启动后会进入一个虚拟的根目录,通过 mount -o remount,rw /sysroot 将磁盘挂载,能够对文件进行读写
修改根目录 ( chroot /sysroot )
设置新密码 echo ${password} | passwd --stdin
设置后需要确保 SELinux 是关闭状态,否则会被安全拦截,通过 vim /etc/selinux/config 可以打开 SELinux 配置文件,将 SELINUX=enforcing 修改为 SELINUX=disabled
配置完成通过 exit 回到虚拟目录,再 reboot 重启
进程管理
进程是操作系统 分配资源的最小单位 。 进程结束的时候不一定会正常结束,也可能通过 ctrl c 或者 single 强制结束,也就是 abort 。
进程可以创建子进程,所以进程也是一棵树。
线程是操作系统 任务调度的最小单位 。 CPU 在分配时间片时,是按照线程来分配的,同一进程创建的线程,将共享资源。
查看进程
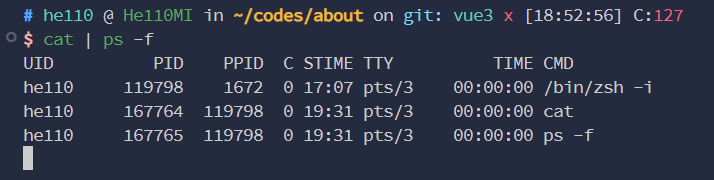
ps: 查看当前终端能查到的进程,PID是进程的唯一标识,CMD是执行的命令ps -e: 查看不同终端的所有进程ps -f: 查看结果携带UID、PPID,即哪个用户启动的,这个UID是可以修改的,不一定准确,PPID是父进程的 ID 。ps -L: 查了线程ps -Z: 查看 SELinux 给打的标签
pstree: 按照PPID聚合成树形结构展示。top: 动态展示进程信息,包括资源使用情况,进程默认每3秒更新一次,可以通过s编辑更新时间up xxx,: 开机到现在运行了多少时间xx users,: 有几个用户登录了load average: xx, xx, xx: 当前系统负载,对应 1 分钟 、 5 分钟 、 15 分钟的资源使用情况。Tasks: 有多少进程在运行,有多少进程在休眠,有多少进程被停止Cpu(s): CPU 使用率,多个 CPU 展示平均值,通过1切换逐个 CPU 展示还是平均值us: 用户计算ni: nice ,即优先级sy: 进程状态交互id: 空闲状态wa: 等待状态
KiB Mem: 内存使用率KiB Swap: Swap 使用率。 Swap 是内存淘汰后临时存放的磁盘空间, Swap 使用率低说明内存负载低,如果内存与 Swap 都满了,会 随机杀掉占用内存较大的进程 。
top -p ${PID}: 只查看指定进程状态
阻塞进程、非阻塞进程
阻塞进程
指正在运行的进程因等待某些事件(如 I/O 操作、资源获取或数据到达)而无法继续执行,主动放弃 CPU 进入阻塞状态的过程。此时,进程会调用阻塞原语将自己挂起,并加入阻塞队列,直到事件触发后被唤醒。
由于每个进程都需要被唤醒,才能知道是否还在阻塞,所以当阻塞的进程数较多时,会出现频繁切换进程的情况,此时会出现大量的性能开销,对应的就是 Apache 、 Tomcat 等服务。
非阻塞进程
非阻塞进程通过异步控制,在资源准备完成后主动唤醒进程,避免了频繁的进程切换开销。
在进程发起非阻塞操作时,系统调用会返回 EAGAN 错误,而不是阻塞进程,这样可以在软件层面通过主动轮询或者事件驱动,在资源准备完毕后才去唤醒进程,典型事例有 nginx 。
进程控制
优先级控制
nice -n ${value} ${file}: 设定文件运行时的优先级。${value}范围为[-20, 19],值越小优先级越高。renice -n ${value} ${PID}: 设置运行中的进程的优先级。
作业控制
&: 放到命令末尾,命令会放到到后台运行。ctrl z: 暂停当前命令,并将当前运行的命令切换到后台。jobs: 查看所有后台运行的进程。fg ${value}: 将后台进程切换到前台,${value}从jobs获取,最前面的数字即为${value}
进程间通信
kill -l: 查看当前支持的所有信号SIGINT: 中断程序,对应-2SIGKILL: 无条件立即结束,对应-9
守护进程( daemon )
- 守护进程: 完全脱离终端控制(即使启动时依赖终端),不接收终端信号(如
SIGHUP),且不向终端输出信息,通常随着操作系统长期运行。 nohup进程: 仅忽略SIGHUP信号(终端挂断信号),但未完全脱离终端。
nohup
nohup 会忽略 HANGUP 信号,终端关闭了也不会关闭进程。
一般会在后台启动,也就是配合 & 使用,例如: nohup tail -f /var/log/messages & ,期间所有输出会放到 ./nohup.out 。
当 nohup 启动后,关闭终端,进程对应的父进程会被杀死,此时进程会变成孤儿进程,被 1 号进程收留,所以 PPID 也会随之改变。
查看守护进程
/proc 目录会在被访问时,读取内存信息,映射到本地文件中,通过这种方式可以读取守护进程的信息。
通过 /proc/${PID} 可以查看内存映射出来的进程内容。
- 查看进程的文件操作可以直接看
ls -l fd - 查看进程的执行根目录可以直接看
ls -l cwd
系统日志
系统日志一般存放在 /var/log 目录下
/var/log/message: 系统实时输出的信息/var/log/dmesg: 内核启动时打印的信息/var/log/secure: 安全日志/var/log/cron: 计划任务日志
安全策略
MAC: 强制访问控制,即操作系统内部强制校验,为进程、文件、用户打标签,判断是否匹配,如果不匹配就禁止访问,所以重置密码的时候需要关闭SELinux,也就是MACDAC: 自主访问控制,即用户通过权限、用户组等方式自行实现的访问控制能力
内存与磁盘
查看信息
查看内存信息
free: 查看内存与 Swap 分区使用情况free -m: 格式化单位,单位为 MB ,小数部分会被舍弃free -g: 格式化单位,单位为 GB ,小数部分会被舍弃total: 所有内存used: 已被使用的内存free: 空闲内存buff/cache: 缓存区内存available: 由于 Linux 进程会尽可能多的占用空闲内存,所以有一部分是申请了但是没有使用的,就是available
top: 实时查看内存占用以及其他信息
查看磁盘信息
fdisk: 查看分区fdisk -l: 查看所有磁盘,磁盘命名一般为/dev/sda、/dev/sdb,可以查看磁盘大小、扇区、 I/O 速度等。等同于parted -lls /dev/sd?? -l: 查看所有磁盘的所有分区,磁盘命名一般为/dev/sda1、/dev/sdb1
df: 查看磁盘挂载点df -h: 查看磁盘挂载点,输出格式化后的内容
du: 查看文件占用多少空间,包含空洞。
文件系统
文件系统类型
ext4: CentOS 6 以及更早版本默认使用XFS: CentOS 7 以及更晚版本默认使用NTFS: 需要额外安装软件包,有版权限制,否则只读
ext4 包含以下内容:
- 超级块: 记录分区中包含的文件以及文件总数,
df就是直接读的这个信息 - 超级块副本: 数据备份,恢复数据时就是将副本内的数据恢复到超级块
- i 节点: 记录每个文件的信息,包括大小、权限、内容等,但是不包括文件名,文件名存放在上级目录中
- 数据块: 储存 i 节点的数据, i 节点可能不止对应一个数据块,看节点的数据大小
文件操作
touch ${file}: 创建文件echo 123 > ${file}: 写入文件,会为 inode 挂载数据块,一个数据块最少为 4kb ,可以通过du -h ${file}验证cp ${fromFile} ${toFile}: 拷贝文件mv ${fromFile} ${toFile}: 同目录修改的话,只修改目录中存储的文件名,跨目录移动需要迁移数据块,耗时长vim ${file}:vim本质上是复制了一份数据块与 inode ,放到${file}.swap,在保存时修改目录的文件名指针指向${file}.swap,这样可以避免编辑过程中宕机等事故,导致脏数据污染源文件。rm ${file}: 仅断开文件名与 inode 链接ln ${file} ${newFile}: 将新文件名指向${file}对应的 inode ,只能同分区使用ln -s ${file} ${newFile}: 创建符号链接,新文件名对应的不是 inode ,而是源文件的路径,适合跨磁盘、跨文件系统使用
文件访问控制
facl 可以提供比 rwx 更精细的权限控制能力
getfacl ${file}: 查看文件的facl策略setfacl -m u:${user}:r ${file}: 新增facl策略,添加 指定用户 读权限setfacl -m g:${group}:w ${file}: 新增facl策略,添加 指定用户组 写权限setfacl -s u:${user}:r ${file}: 新增facl策略,收回 指定用户 读权限
磁盘分区
如果磁盘小于 2T 可以使用 fdisk 分区
fdisk /dev/sda: 磁盘分区,一块磁盘最多有 4 个主分区,其余为扩展分区。d: 删除分区n: 创建分区q: 退出分区并且不保存w: 保存分区方案并退出p: 打印当前的分区方案
mkfs.ext4 /dev/sda1: 设置分区的文件系统类型为ext4,并进行分区mount -t ext4 /dev/sda1 /mnt/sda1: 手动将磁盘挂载到文件系统上,未挂载不能直接访问-t ext4: 指定文件系统为ext4-t auto: 文件系统自动检查,如果没有传递-t默认就是自动检测
mount 只能手动挂载,重启设备后就丢失,需要重新挂载,可以将磁盘信息写入 /etc/fstab ,即可自动挂载,例如在 /etc/fstab 新增如下一行
# 磁盘 挂载地址 文件格式 磁盘权限 磁盘是否需要备份 开机自检时,检查顺序, 0 为不检查
/dev/sda1 /mnt/sda1 ext4 defaults 0 0超过 2T 需要使用 parted 分区,基本流程相同,语法有所不同
用户磁盘配额
xfs 文件系统的用户磁盘配额 quota
fdisk /dev/sdbmkfs.xfs /dev/sdb1: 使用 xfs 格式化磁盘分区,如果格式化前后磁盘分区是不同文件系统,则需要使用-fmkdir -p /mnt/disk1: 如果目录不存在,则自动创建目录mount -o uquota,gquota /dev/sdb1 /mnt/disk1: 挂载磁盘,uquota是用户配额限制,gquota是用户组配额限制chmod 1777 /mnt/disk1: 修改磁盘权限,方便处理,非必要xfs_quota -x -c 'report -ugibh' /mnt/disk1: 查看磁盘报告-u: 查看用户配额-g: 查看用户组配额-i: 查看 inode 信息-d: 查看 数据块 信息-h: 格式化展示信息
xfs_quota -x -c 'limit -u isoft=5 ihard=10 userl' /mnt/disk1: 添加磁盘配额限制-u: 限制用户配额-g: 限制用户组配额isoft: inode 软限制,实际允许超过,但是会提示ihard: inode 硬限制,绝对不允许超过bsoft: 数据块软限制,实际允许超过,但是会提示bhard: 数据块硬限制,绝对不允许超过
Swap 分区管理
创建 Swap 分区流程:
fdisk /dev/sdcmkswap /dev/sdc1: 格式化为 Swap 分区,实际为打上 Swap 标签swapon /dev/sdc1: 打开 Swap 分区,此时就会追加到 Swap 中了swapoff /dev/sdc1: 关闭 Swap 分区,此时就会从 Swap 中移除了
使用文件作为 Swap 分区:
dd if=/dev/zero bs=4M count=1024 of=/swapfile: 创建 4G 大的空洞文件作为 Swap 分区mkswap /swapfile: 格式化为 Swap 分区,实际为打上 Swap 标签,建议权限改为 600 ,否则可能会报错
如果需要永久生效,也需要写入 /etc/fstab:
# 磁盘 挂载地址 文件格式 磁盘权限 磁盘是否需要备份 开机自检时,检查顺序, 0 为不检查
/swapfile swap swap defaults 0 0磁盘 RAID
RAID 即为磁盘组合使用,类似集群的概念,有专用的 RAID 磁盘,分为以下四个级别:
- RAID 0 striping 条带模式,数据 1 分为 N ,写入不同磁盘,每个磁盘存储不同的内容
- RAID 1 mirroring 镜像模式,数据同时写入不同磁盘,即磁盘备份
- RAID 5 奇偶校验,一般至少 3 块硬盘,前 2 块硬盘为 RAID 0 ,后一块硬盘写入奇偶校验,通过其中一块硬盘 + 奇偶校验可以还原另一个硬盘数据
- RAID 10 至少 4 块硬盘, 2 块 RAID 1 、 2块 RAID 0
逻辑卷管理
名词:
LVM: 逻辑卷管理器PV: 物理卷, LVM 的最底层存储单元,可以是磁盘、分区、 RAID 设备等。VG: 多个物理卷组合成的卷组LV: 逻辑卷,从卷组中划分出来的虚拟分区,最终被格式化为文件系统,支持动态扩容
创建逻辑卷过程:
pvcreate /dev/sd[a,b,c]1: 将sda1、sdb1、sdc1初始化为 PVpvs: 查看 PV 信息vgcreate vg1 /dev/sda1 /dev/sdb1: 创建卷组vg1,并将sda1、sdb1加入卷组中vgs: 查看 VG 信息lvcreate -L 100M -n lv1 vg1: 在vg1上创建一块逻辑卷lv1,大小为100Mlvs: 查看 LV 信息mkfs.xfs /dev/vg1/lv1: 格式化为 xfs 文件系统mount /dev/vg1/lv1 /mnt/lv: 挂载到系统磁盘
扩容现有磁盘
mount | grep ${dir}: 查看目录在哪块卷组上vgextend ${vg} ${pv}: 将 PV 集成到 VG 中lvextend -L +100M -n ${lv}: 给 LV 扩容xfs_growfs ${lv}: 通知文件系统已经扩容,更新磁盘空间
系统诊断
sar: 系统监控,一般内置sar -u 1 10: 每间隔 1 秒对 CPU 采样,采样 10 次sar -r 1 10: 每间隔 1 秒对 内存 采样,采样 10 次sar -b 1 10: 每间隔 1 秒对 磁盘 I/O 采样,采样 10 次sar -d 1 10: 每间隔 1 秒对 每块磁盘 采样,采样 10 次sar -q 1 10: 每间隔 1 秒对 进程 采样,采样 10 次
iftop -P: 网络监控,需要安装软件包。 类似top一样的展示效果,实时监控网络情况。
shell 脚本
Linux 启动过程
graph TB
BIOS --> MBR
MBR --> BootLoader["BootLoader ( grub )"]
BootLoader --> kernel
kernel --> systemd['systemd ,即 1 号进程,低版本为 init']
systemd --> 系统初始化
系统初始化 --> shellMBR
MBR 即为主引导记录
dd if=/dev/sda of=mbr.bin bs=446 count1: 导出主引导记录dd if=/dev/sda of=mbr.bin bs=512 count1: 导出主引导记录 + 分区表hexdump -C mbr.bin: 读取二进制文件,并展示
BootLoader
BootLoader 即 grub 程序,将引导 Linux 内核启动。
/boot/grub2/grub2-editenv list: 查看引导内核版本
kernel
启动内核,并运行 1 号进程,低版本 Linux 是 init ,高版本为 systemd
systemd
systemd 会按照当前的启动级别,启动不同的进程
shell 语法
shell 文件格式
shell 文件格式如下
#!/bin/bash
# shell 命令当使用 shell 解析器如 bash 、 sh 等工具解析时,会将第一行认为是注释,忽略
当通过 ./test.sh 执行时,会根据第一行注释定义的解析器去执行 shell
#!/bin/bash 也被称为 Sha-Bang
shell 不同执行方式的区别
bash test.sh: 启动子进程去执行,对当前 shell 无影响,如果文件无可执行权限也能被执行。./test.sh: 启动子进程去执行,对当前 shell 无影响,必须要有rx权限。source ./test.sh: 在当前 shell 执行,执行结果会对当前 shell 产生影响,如果文件无可执行权限也能被执行。. ./test.sh: 在当前 shell 执行,执行结果会对当前 shell 产生影响,如果文件无可执行权限也能被执行。
内建命令与外部命令
- 内建命令: shell 执行器自带的命令,不会创建子进程执行
- 外部命令: 不是内建命令的命令,会创建子进程执行
管道
管道可以将不同命令连接起来,将上一个命令的输出,作为下一个命令的输入,持续组合。
| 即为管道符,也称匿名管道,管道符左右两边的命令会创建子进程去执行,并将输入输出进行连接,也即是进程间通信。
由于会创建子进程去执行,所以 内建命令也无法影响到当前 shell
重定向
一个进程默认会打开标准输入、标准输出、错误输出三个文件描述符
<: 输入重定向。${command} < ${file}, 将file的内容作为command的输入>: 输出重定向。${command} > ${file}, 将command的输出写入file(覆盖源文件)>>: 输出重定向。${command} >> ${file}, 将command的输出写入file(追加到文件末尾)2>: 错误重定向。${command} 2> ${file}, 将command的错误信息写入file(覆盖源文件)2>>: 错误重定向。${command} 2>> ${file}, 将command的错误信息写入file(追加到文件末尾)&>: 输出重定向。${command} &> ${file}, 将command的所有信息写入file(覆盖源文件)&>>: 输出重定向。${command} &>> ${file}, 将command的所有信息写入file(追加到文件末尾)
变量
命名规则:
- 字母、数字、下划线
- 不能以数字开头
变量赋值:
a=123: 变量名=变量值,=两端不能有空格,否则会被视为命令let a=10+20: 定义变量的时候支持对变量进行计算l=ls: 可以将命令设置为变量letc=$(ls -l /etc): 将命令输出赋值给变量,也可以使用反引号替代$()
变量作用域只在当前 shell ,不能跨 shell 使用,打开新终端时变量会自动失效。
通过 export ${变量名} 可以导出变量,让子进程也能访问该变量
unset ${变量名} 可以删除变量
环境变量
env | more: 查看当前定义的环境变量PATH=$PATH:/xxx: 创建一个变量,值为全局PATH变量 +/xxx,该变量需要被export,才能在创建新终端后也生效echo $?: 上条命令的结束代码, 0 为没有错误,或者表示条件判断为trueecho $$: 输出当前进程 PIDecho $0: 输出当前进程名称echo $1: 输出进程接受的第 1 个参数echo ${2-default}: 输出进程接受的第 2 个参数,如果参数值为空,设置为defaultecho $*: 输出所有参数列表,为字符串拼接形式echo $@: 输出所有参数列表,为数组形式echo $#: 添加到 shell 的参数个数
以下文件会被自动执行,同时对环境变量进行初始化:
/etc/profile: 全局环境变量,对所有用户生效/etc/profile.d/: 存放全局环境变量的目录,自动加载,对所有用户生效/etc/bashrc: 存放全局环境变量的文件,bash自动加载,对所有用户生效~/.bash_profile: 全局环境变量,仅对当前用户生效~/.bashrc: 存放全局环境变量的文件,bash自动加载,仅对当前用户生效
通过 su - ${user} 切换用户时,自动加载 shell 的执行顺序为:
/etc/profile~/.bash_profile~/.bashrc/etc/bashrc
通过 su ${user} 切换用户时,自动加载 shell 的执行顺序为:
~/.bashrc/etc/bashrc
通过 bash 创建新终端,自动加载 shell 的执行顺序为:
~/.bashrc/etc/bashrc
数组
list=(1 2 3): 定义数组echo ${list}: 输出数组第 1 个元素echo ${list[@]}: 输出数组所有元素echo ${#list[@]}: 输出数组元素数量echo ${list[1]}: 输出数组第 2 个元素
运算符
expr 1 + 1: 计算1 + 1的结果,只能计算整数,中间必须有空格let a=1+1: 可以实现与expr一样的计算效果,并且支持小数,中间不能有空格(( a++ )):let的语法糖,里面的表达式可以插入空格
引号
- ': 不会解析变量
- ": 会解析变量
- `: 执行命令
括号
( ${command} ): 创建一个子 shell 执行命令( 1 2 ): 创建数组(( 1 + 2 )): 执行计算$(ls): 执行ls命令[ 1 -gt 2 ]: 进行条件判断,等同于test 1 -gt 2,两边必须有空格[[ 1 = 2 ]]: 进行条件判断, 1 是否等于 2 ,支持符号写法,也就是>、<,两边必须有空格<: 输入重定向>: 输出重定向{0..9}: 输出0-9cp -v /etc/passwd{,.bak}: 简化写法,等同于cp -v /etc/passwd /etc/passwd.bak
判断语句
可以使用 test 命令与 [[]] 进行条件判断, [[]] 对 test 做了扩充,支持符号写法,比如 > 、 < 等等。
除此之外, shell 中的判断还支持对文件的判断,毕竟 Linux 一切皆文件:
-b ${file}: 文件存在,并且是特殊块-c ${file}: 文件存在,并且是特殊字符-d ${file}: 文件存在,并且是目录-e ${file}: 文件存在-f ${file}: 文件存在,并且是常规文件-r ${file}: 文件存在,并且是有可读权限-w ${file}: 文件存在,并且是有可写权限-x ${file}: 文件存在,并且是有可执行权限
在 test 执行后,可以通过 $? 获取判断结果,不一定需要把结果保存为单独变量。
条件语句
# 只是对测试条件的 $? 判断,一般会使用 test 命令作为 if 判断条件
if [ -x /tmp/test.sh ]
# 如果 then 单独一行, if 后可以不跟 `;` ,否则一定要跟 `;`
then
# 测试条件返回为 0 时执行
fi
# 使用 echo 命令作为判断条件,由于 echo 1 没有错误,所以此时 $? 是 0 ,那就会输出 'true'
if echo 1; then
# 这里可以执行多条命令,块已经被 then 到 else/fi 包裹,不需要额外处理
echo 'true'
echo 'true'
echo 'true'
else
# 测试条件返回不为 0 时执行
echo 'false'
fi
# 判断是不是 root
# $USER 和 root 的 引号 可加可不加,两者都能识别。
# 如果判断的值不确定的话,推荐都加上,避免出现奇怪的问题
if [[ $USER = root ]]; then
echo 'root 用户'
# 可以通过 elif 在上面规则不满足时,继续判断, elif 后也需要跟 then
elif [[ "$USER" = 'he110' ]]; then
echo 'He110 用户'
else
echo 'false'
fi分支语句
shell 中可以用 case 实现 JS 中的 switch 分支语句效果, case 基本格式如下:
case "$变量" in
"值 1" )
# 这里需要两个 ;
# 第一个 ; 结束分支内执行的命令
# 第二个 ; 才是结束分支
;;
# 可能有多个值匹配同一分支的情况,直接用 | 连接即可
"值 2" | "值 3" )
;;
# 通配符,等同于 switch 中的 default
* )
;;
esac循环语句
# 使用 {start..end} 可以生成 [start, end] 区间内的整数数组
# 这里可以替换为其他数组,比如参数数组 `$*` 、 `"$@"`
# 遍历的时候每个数组元素会放到 item 变量中
for item in {1..9}
# 通过 do 语句定义循环体
do
# 循环体内部执行的命令
echo "print $item"
# 通过 done 表示循环体定义完成
done批量重命名:
# 从命令中读取列表
for filename in `ls *.mp3`
do
# 通过 $() 执行命令,获取文件名
# 重命名为 xxx.mp4
mv $filename $(basename $filename .mp3).mp4
done
# 另一种写法,可以直接遍历文件
for filename in ./*.mp3
do
mv $filename $(basename $filename .mp3).mp4
doneC 语言风格的遍历(不推荐, shell 不适合做计算,效率不高)
for (( i = 1; i <= 10; i++ ))
do
echo "print $i"
donewhile / until 循环:
# while 判断条件为 true 时执行
while [ 2 -gt 1 ]
do
echo '死循环了'
done
# 死循环的简洁构建方式,比如用于输出交互式菜单
while :
do
echo '死循环了'
done
# while 判断条件为 false 时执行
until [ 1 -gt 2 ]
do
echo '死循环了'
donebreak / continue 可以控制循环退出:
for num in {1..9}
do
if [ $num -eq 5 ]; then
# 跳过这次循环
continue
elif [ $num -eq 8 ]; then
# 结束循环
break
else
echo $num
fi
done遍历参数的 N 种方式:
# for 循环遍历
for pos in $*
do
# 这里最好加上 "" ,确保进行字符串比较,避免出现一些参数类型导致的问题
if [ "$pos" -eq 'help' ]; then
echo "$pos"
fi
done
# while + shift 参数左移
# 判断参数个数 > 1 就继续循环
while [ $# -ge 1 ]
do
if [ "$1" -eq 'help' ]; then
echo "$1"
fi
# 将参数出队
# shift 后可以跟整数,表示一次出队多少个参数
# 适用于 -a xxx -b xxx 的情况
shift
done函数
基本结构如下:
# 定义函数, function 可省略
function funcName() {
# a 在函数被调用时创建
# 调用结束自动销毁
# 局部变量可以避免对外部 shell 环境污染
local a=2
echo $a
}
# 执行函数
funcName系统内置的函数库位于 /etc/init.d/functions ,定义了操作系统内置的一些函数。
脚本控制
脚本控制是为了避免用户死循环占用资源,比如递归创建子进程,最终对所有用户产生影响。
使用 ulimit -a 可以看到当前终端的使用限制,比如 CPU 限制、进程数限制、锁限制等等。
fork 炸弹
fork 炸弹指不断递归创建子进程,最终将资源占满的恶意代码,例如:
# 定义了一个 func , func 会递归在后台启动 func
# 最终后台被大量进程占满,导致资源不足
func() { func | func& }; func精简命名后,可以更短,例如:
.(){.|.&};.一般通过资源监控可以发现此类程序,并通过 renice 调整优先级,或者直接 kill -9 终止。
信号
信号广泛用于进程间通信,是 Linux 的底层通信机制之一。
kill可以给指定进程发送信号,默认发送 15 号信号。ctrl c会发送 2 号信号。kill -9会强制终止,不可捕获,不可阻塞。
进程捕获信号示例:
# trap 捕获后的操作 捕获的信号码
trap "echo signal" 15
# ctrl + c 也是可以被捕获的,并修改为不被终止,可以用于备份脚本等后台进程
trap "echo '不可被 ctrl + c 制裁'" 2计划任务
计划任务分为一次性与周期性
一次性计划任务
一次性计划任务只会执行一次,使用 at ${date} 创建计划任务,输入脚本后按 ctrl + d 完成创建。
使用 atq: 查询所有一次性计划任务。
由于定时任务执行时 shell 环境不可测,推荐不依赖环境写法,比如使用绝对路径。
定时任务执行的时候不依赖终端,所以也没有标准输出,获取输出需要依靠 > 重定向。
周期性定时任务
周期性定时任务每隔一段时间执行一次, Linux 提供了 cron 实现定时任务,最小单位为 1 分钟,如果使用秒级定时器、毫秒级定时器,需要使用第三方依赖包。
crontab -e: 创建周期性定时任务crontab -l: 列出所有周期性定时任务
如下是一个配置自动清理缓存的脚本:
# 分钟 小时 天 月 星期 需要执行的命令
# * 匹配任意时间
# */5 即为每五分钟运行一次
# 如果需要指定时间,直接写时间数字即可
# 需要指定时间段可以使用 1-5
# `/usr/bin/sync`: 会将内存中的缓存持久化(如果需要的话),避免清理缓存时导致数据丢失
# `echo 1 > /proc/sys/vm/drop_caches`: 清理内存中的缓存
*/5 * * * * /usr/bin/sync; echo 1 > /proc/sys/vm/drop_caches
# 每周一的凌晨 3:30 定时执行备份任务
30 3 * * 1 /root/backup.sh延时计划任务
anacon 机制,即延时计划任务,当到达定时任务执行时间,但是系统不可用(如关机等),可以在系统可用后立即执行
anacron 通过检查 /var/spool/anacron/ 目录下的时间戳文件,判断任务是否在预定周期内执行过。若因系统关机导致任务未执行,会在下次开机后自动补执行
通过编辑 /etc/anacrontab 可以创建延时计划任务,内置的延时定时任务如下:
# 全局参数
RANDOM_DELAY=45 # 最大随机延迟时间(分钟)
START_HOURS_RANGE=3-22 # 允许执行的时间段(小时范围)
# 任务定义格式
# 任务周期 基础延迟时间 任务唯一标识符 实际需要执行的任务或者脚本命令
period_in_days delay_in_minutes job_identifier command
1 5 cron.daily nice run-parts /etc/cron.daily
7 25 cron.weekly nice run-parts /etc/cron.weekly
@monthly 45 cron.monthly nice run-parts /etc/cron.monthly每个任务可以设置基础延迟时间与随机延迟范围
锁
flock -xn "/tmp/task.lock" -c "/root/task.sh"flock: 为指定任务创建锁文件,只要锁文件存在,再次使用该锁文件执行任务就会被限制。-x: 独占锁。只要被锁定了,不能再重复运行其他任务。-s: 共享锁。允许多个进程一起持有锁,但是只能读,不能写。 如果已经被独占锁锁住,即使共享锁也无法读。-n: 非阻塞模式。如果被锁住了就直接结束,而不是持续等待锁释放。-w: 阻塞模式最长等待多少秒。"/tmp/task.lock": 锁文件存放位置-c "/root/task.sh": 配置需要执行的任务/命令
搜索
正则
基本与 JS 中的正则相同
内容查找
grep 可以对文件内容进行查找,基本命令格式为: grep ${keyword} ${待查找的内容或者文件名} 。 例如: grep html ./index.html
${keyword} 可以使用正则表达式,例如 grep "<ht.*" ./index.html 。
使用正则表达式时,最好将正则表达式使用 " 包裹,避免 shell 解析时识别将部分元字符解析为其他 shell 关键字。
文件查找
find 可以对文件进行查找,例如 find ${需要查找的文件名} 。 这将在当前目录下查找指定文件名,这里的文件名需要精确匹配,支持 shell 通配符,不支持正则表达式。
比较常见的基本命令格式为: find ${需要查找的目录} ${查找条件} 。 例如:
find /var/log -name nginx: 将会查找/var/log目录下所有文件名包含nginx的字符的任意文件。find /var/log -regex .*nginx.*: 将会查找/var/log目录下所有文件名包含nginx的字符的任意文件,使用正则匹配查找。find /var/log -type f -regex .*nginx.*: 将会查找/var/log目录下所有文件名包含nginx的字符的普通文件,使用正则匹配查找。find /var/log -atime 8:atime对应文件被访问的时间,这里查找的是 8 小时内被访问过的文件。可以使用stat ${file}查看atime。find /var/log -ctime 8:ctime对应 inode 的更新时间,例如文件创建、数据块更新、权限变更等。可以使用stat ${file}查看ctime。find /var/log -mtime 8:mtime在内容被修改时更新,这里查找的事 8 小时内被更新过内容的文件。可以使用stat ${file}查看mtime。find /var/log -user root: 查找归属于 root 用户的文件。find /var/log -uid 0: 查找归属于 root 用户的文件。find *log* -exec ${command}: 查找所有包含 log 的文件,并对这些文件执行${command},例如find *log* -exec rm -v {} \;{}: 在${command}中,可以使用{}引用遍历出来的每个文件\;: 表示传给-exec的值传完了,必须要加
文本操作
cut 可以将文件、内容进行切分,并按照需要返回对应的内容块。
常见用法如: cut -d ${separator} -f 1 ${file} 。 这个命令将指定内容按照 ${separator} 分割,并获取其中的第 1 个部分。
传入文件后,将按照换行符,每一行文件都进行切分。
例如: cut -d ":" -f 7 /etc/passwd: 查询所有用户访问的终端。
sort 可以对内容进行排序,例如 cut -d ":" -f 7 /etc/passwd | sort 会对所有终端进行排序, sort -r 会反向排序
uniq -c 将会对文本进行统计,合并相邻的相同文本,并计算次数。
所以统计所有用户使用的终端,并按照使用次数排序,就是 cut -d ":" -f 7 /etc/passwd | sort | uniq -c | sort -r
先分割所有的终端,并将终端排序,确保相同终端一定相邻,再合并终端名,并计次,最终倒序输出,确保次数高的在前面。
行文本编辑器
vim是全文本编辑器,主要用于编辑文件,一般是交互式的。sed与awk是行文本编辑器,逐行处理文本,一般是非交互式的。
sed
sed 一般用于文本替换,例如 sed '${寻址空间}s/${查找文本}/${替换文本}/' ${file1} [ ${file2} ] ,寻址空间和查找文本可以是正则表达式,寻址空间用于对待匹配文本进行过滤,可以指定行号或者指定满足正则匹配的行。
sed 的基本工作方式是:
- 将文件以行为单位读取到内存(模式空间)
- 使用
sed的每个脚本对该行进行操作 - 处理完成后输出该行
文本替换
多个替换可以使用 -e 组合,例如 sed -e 's/{old1}/${new1}/' -e 's/{old2}/${new2}/' ${file}
需要将替换的内容写回文件可以使用 -i ,例如: sed -i 's/{old1}/${new1}/' ${file}
需要使用扩展正则表达式可以使用 -r ,例如: sed -r 's/{扩展正则}/${new1}/' ${file} 使用推荐直接开 -r ,如捕获组之类的功能都属于扩展功能。
# 创建测试文件,只有一行,内容为 'a a a'
echo a a a > testFile
# 输出 `aa a a` ,替换每行仅发生一次
sed 's/a/aa/' testFile
# 输出 `aa aa aa` ,替换每行仅发生一次,但是每次都替换全部匹配项
sed 's/a/aa/g' testFile
# -n 可以阻止 sed 默认的输出行为
# p 表示将匹配的行,替换后输出
# 这条语句将只输出替换成功的行
sed -n 's/a/aa/p' testFile
# `w ${file}` 将替换成功的行写入新文件
sed -n 's/a/aa/w wFile' testFile
# 当替换 / 时,可以将原本的分隔符替换成别的字符,类似 JS 正则
sed 's!/!aa!' testFile
# 输出 `bb a a` , -e 参数依次执行,第二个 -e 可以拿到第一个 -e 返回的 aa
sed -e 's/a/aa/' -e 's/aa/bb/' testFile
# 输出 `bb a a` , 等价于上一条,简略写法
sed 's/a/aa/;s/aa/bb/' testFile
# 没有输出,直接将 `bb a a` 写入源文件中对应行
sed -i 's/a/aa/;s/aa/bb/' testFile
# 另存为一个新文件,内容为 `bb bb a`
sed 's/a/aa/;s/aa/bb/' > otherTestFile
# 删除前面三个字符,输出 `a a`
sed 's/...//' testFile
# 输出 'bbbb a a'
sed -r 's/(bb)/\1\1/' testFile
# 保存替换模式到文件
echo 's/...//' > sedscript
# 从文件中加载替换模式
sed -f sedscript filename寻址空间
寻址空间的使用示例如下:
# 创建一个多行的文件
echo 1 2 3 > testFile
echo a b c >> testFile
# 匹配第一行的 a 并替换为 b
# 这里不会发生替换,因为第一行没有 a
sed '1s/a/b/' testFile
# 匹配第 1 行到第 2 行的 a 并替换为 b
# 这里会发生替换,因为第 2 行有 a
sed '1,2s/a/b/' testFile
# 匹配第 1 行到最后 1 行的 a 并替换为 b
# 这里会发生替换,因为第 2 行有 a
sed '1,$s/a/b/' testFile
# 匹配行内存在 \w 也就是字母的行,并执行替换
sed '/\w/s/a/b/' testFile
# 匹配行内存在 \w 也就是字母的行,并执行多次替换
sed '/\w/{s/a/b/;s/b/aa/}' testFile其他功能
除了替换之外, sed 还支持其他能力:
- 删除行:
sed '/a/d' testFile: 使用寻址空间匹配含有'a'的行,并将其删除,并忽略其后跟着的命令sed '/a/d;s/a/b/' testFile: 使用寻址空间匹配含有'a'的行,并将其删除,后续的替换命令被忽略,不会执行
- 追加行:
sed '/a/i xxx' testFile: 使用寻址空间匹配含有'a'的行,并在其上一行插入'xxx'sed '/a/a xxx' testFile: 使用寻址空间匹配含有'a'的行,并在其下一行插入'xxx'
- 修改匹配行:
sed '/a/c xxx' testFile: 使用寻址空间匹配含有'a'的行,将这一行修改为'xxx'
- 读写文件:
sed '/a/r templateFile' testFile: 使用寻址空间匹配含有'a'的行,将这一行的内容修改为templateFile的文件内容sed -n 's/a/aa/w wFile' testFile: 替换后的文件写入指定文件,可用于多文件合并
- 打印:
sed '/a/=' testFile: 使用寻址空间匹配含有'a'的行,并在其上一行插入该行对应的行号,一般要配合-nsed '/a/p' testFile: 使用寻址空间匹配含有'a'的行,并输出该行,一般要配合-n
- 提前退出:
sed '10q' testFile: 只打印前十行,然后直接退出,性能更高
- 多行匹配:
sed 'N;s/\n//' testFile: 将下一行文本一起读入,然后将换行符替换为空字符串P: 打印D: 删除
多行匹配实例
多行匹配实例:
# 创建一个多行文本,两个 hello bash 拆分成 3 行
cat > testFile << EOF
hell
o bash hel
lo bash
EOF
# 1. 读入 1-2 行
# 2. 删除 \n
# 3. 匹配 `\s?hello bash` 并替换为 `hello zsh`
# 4. 打印替换结果
# 5. 将输出的内容删除掉
# 6. 读入第 3 行,并与剩余字符串合并,重新执行 2
# 最终输出:
# hello zsh
# hello zsh
sed -r 'N;s/\n//;s/\s?hello bash/hello zsh\n/;P;D' testFile保持空间
保持空间可以保持处理中的文本,以便下次使用,而不需要一直 P;D
保持空间默认会有一行空白行,也就是 \n
h和H将模式空间内容存放到保持空间,小写是覆盖模式,大写是追加模式g和G将保持空间内容取出到模式空间,小写是覆盖模式,大写是追加模式×交换模式空间和保持空间内容
# 需求: 将 /etc/passwd 前 5 行倒序输出
# 命令写法如下,可以用 tac 替换 sort -r
head -5 /etc/passwd | cat -n | sort -r
# 使用 sed 处理命令如下
# 由于 sed 每次只读一行,之前的行会被丢弃,所以需要利用交换模式,每次读取前,先从保持空间获取之前读过的内容。
# 处理逻辑如下:
# 1. 使用 `1h` 将第一行放入保持空间,覆盖掉原来的空白行
# 2. 使用 `1!G` 表示除了第一行,每次模式空间读取新行后,都从保持空间获取历史值,并追加到模式空间中,也就是逆序排列
# 3. 使用 `$!x` 表示除了最后一行,否则读取后都将模式空间与保持空间内容交换
# 4. 使用 `$p` 表示只有最后一行才会输出
head -5 /etc/passwd | cat -n | sed -n '1h;1!G;$!x;$p'
# 另一套处理思路为追加模式,每次都将内容追加进保持空间,而不需要交换
# 处理逻辑如下:
# 1. 使用 `1!G` 表示除了第一行(此时保持空间有一行空白行),其他行读取新行后,都从保持空间获取历史值,并追加到模式空间中,也就是逆序排列
# 2. 使用 `h` 将结果保存到保持空间中
# 3. 使用 `$p` 表示只有最后一行才会输出
head -5 /etc/passwd | cat -n | sed -n '1!G;h;$p'awk
awk 一般用于对文本内容进行统计,并按照格式输出,通常要求文本具备一定的规范性,如果不规范的话可以先用 sed 处理后再统计,例如: awk -F ':' '{print $NF}' /etc/passwd 将统计 /etc/passwd 中定义的所有终端
名词解释
awk 中常用名词:
- 记录: 每一行就是一项记录
- 字段: 使用分隔符分隔开的内容,就是字段。默认分隔符为 空格与制表符。 可以使用
-F指定字段分隔符:awk -F '${新的分隔符,支持正则}' - 主输入循环:
{ }内的内容,其中的代码会对每个记录生效 - 开始语句:
BEGIN { }内的内容,其中的代码会在主循环开始之前执行一次, 大小写敏感 - 结束语句:
END { }内的内容,其中的代码会在主循环开始执行完成后执行一次, 大小写敏感
# 输出安装的内核版本
# 通过 /^menu/ 过滤行,只取 menu 开头的行给 awk 处理
awk -F "'" '/^menu/{ print $2 }' /boot/grub2/grub.cfg
# 输出安装的内核版本,并添加序号
# x 为变量,未定义会初始化为 0
# x++ 会在每次循环时自增
awk -F "'" '/^menu/{ print x++,$2 }' /boot/grub2/grub.cfg表达式
- 赋值操作符:
var1 = 'name'var2 = 'hello' 'world', 自动连接多个字符,变成'helloworld'var3 = $1, 分隔符分割后,切割出来的第一个字段num++num--num += 1num -= 1num *= 1num /= 1num %= 1num ^= 1
- 算数操作符:
+-*/%^
- 系统变量:
awk相当于一门编程语言,也有自己的系统变量,就像NodeJS的process一样FS: 输入的字段分隔符。输入时会按照FS对记录进行分割。awk 'BEGIN{FS=":"}{print $NF}' /etc/passwd: 统计/etc/passwd中定义的所有终端
OFS: 输出的字段分隔符。输出时会按照FS对字段进行拼接。awk 'BEGIN{FS=":";OFS="---"}{print $1,$NF}' /etc/passwd: 统计/etc/passwd中定义的所有用户与终端,用户与终端使用---连接
RS: 记录分隔符,默认为换行符NR: 行数。多个文件时,会持续累计。awk '{print NR,$0}' /etc/passwd /etc/passwd
FNR: 行数。多个文件时,新文件第一行重置为1。awk '{print FNR,$0}' /etc/passwd /etc/passwd
NF: 字段数量。直接输出对应字段数量,取最后一个字段通常使用$NF。awk 'BEGIN{FS=":"}{print $NF,NF}' /etc/passwd: 统计/etc/passwd中定义的所有终端,并在后面跟上字段数量,也就是7
- 关系操作符
><<=>===!=~: 匹配正则表达式!~: 不匹配正则表达式
- 布尔操作符:
&&||!
判断和循环
awk 中的判断和循环,与 JS 语言风格是一致的,一模一样:
ifwhiledo-whilefor
数组
awk 的数组类似 JS ,数组下标可以是字符串,没有数组方法的概念。
# 初始化文件
echo user1 1 1 1 > test.txt
echo user2 2 2 2 >> test.txt
# 遍历文件行,输出每行的数字之和,即:
# user1 3
# user2 6
awk '{ sum = 0; for (col = 2; col <= NF; col++) { sum += $col; } list[$1] = sum } END { for (user in list) { print user, list[user] } }' test.txt
# awk 同样可以使用 -f 加载代码块,并且可以读取 awk 的命令行参数
# ARGC 是参数数量
# ARGV 是参数值数组
cat > args.awk << EOF
BEGIN {
for (x = 0; x < ARGC; x++) {
print x, ARGV[x]
}
}
EOF
# 输出结果如下:
# 0 awk
# 1 111
# 2 222
# 3 333
awk -f args.awk 111 222 333函数
awk 的函数分为 3 类:
- 算数函数: 处理数字的。可以通过
man awk查看所有支持的函数。sin(): 正弦函数cos(): 余弦函数int(): 取整rand(): 伪随机数, 0-1 之间,每次取的值都一样srand(): 安全的随机数, 0-1 之间,每次取的值都不一样
- 字符串函数: 处理字符串的。可以通过
man awk查看所有支持的函数。sub(old, new, str): 替换第一个匹配项old支持字符串或者正则表达式gsub(old, new, str): 全局替换,old支持字符串或者正则表达式index(str, subStr): 查找子串在父串中出现的位置length(str): 返回字符串长度match(str, regexp, arr): 正则匹配,arr可省略,用于存储匹配分组的数组,如果需要捕获自组则需要传入split(str, arr, sep): 将str按sep分割,分割后存入arr中substr(str, pos, len): 截取子字符串。 从pos开始截取,取len个字符,pos从1开始
- 自定义函数: 自定义的处理项。跟
JS定义函数一样,但是必须定义到BEGIN{}、{}、END{}外面。
防火墙
分类
按照运行环境分为:
- 软件防火墙: 主要处理数据包过滤、地址转换等
- 硬件防火墙: 主要面向 DDos 等网络攻击场景,也能兼顾处理一部分包过滤,
按照服务的网络层分为:
- 包过滤防火墙: 从传输层控制数据包过滤、地址转换等
- 应用层防火墙: 应用层能获取更多的信息,比如按登录用户过滤
CentOS 6 默认使用 iptables ( 底层为 netfilter ) CentOS 7 默认使用 firewallD ( 会转换成 iptables 处理,简化配置 )
iptabls
名词解释
- 规则表: 按照不同的操作类型进行规则配置,比如 filter 表、 NAT 表、 mangle 表、 raw 表,规则表内
- filter 表: 数据包过滤
- nat 表: 地址转换
- mangle 表: 对数据包进行修改
- raw 表: iptables 默认开启对数据包的连接追踪,此表配置哪些数据包不追踪。
- security 表: 此表用于强制访问控制 (MAC) 网络规则,例如由 SECMARK 和 CONNSECMARK 目标启用的规则,主要用于 SELinux ,不常用。
- 规则链: 按照网络传输链路过程进行规则配置,比如
INPUT、OUTPUT、FORWARD、PREROUTING、POSTROUTING。 更具体的说,规则链是按照netfilter不同hook监听来聚合规则的,比如都监听INPUT,所以规则链也是支持用户自定义的。
基本语法
iptables 常用语法为 iptables -t ${规则表} ${command} ${规则链} ${规则}
-t ${规则表}: 针对哪个规则表进行操作,如果没有指定则默认为 filter 表${command}: 选择需要执行的命令,例如查看规则、新增规则、删除规则、修改规则-A/--append: 添加规则,追加到规则表末尾-C/--check: 检查是否匹配规则-D/--delete: 删除规则/规则链-I/--insert: 在规则链的指定位置插入一个或多个规则-R/--replace: 替换指定的规则-P/--policy: 配置规则链的默认策略-L/--list: 列出规则,如果没有指定规则规则链,将列出表中所有的规则-N/--new-chain: 创建自定义的规则链-X/--delete-chain: 删除自定义的规则链-E/--rename-chain: 重命名自定义的规则链-n: 不根据 IP 反向索引主机名,直接展示 IP-v: 查看详细信息
${规则链}: 在传输链路的哪个位置进行操作${规则}: 具体进行什么操作,比如允许通过、不允许通过-4/--ipv4: 规则用于 IPv4-6/--ipv6: 规则用于 IPv6-p/--protocol: 规则针对指定通信协议生效--dport: 规则针对指定端口生效-s/--source: 规则针对指定源地址,支持ip[/mask]-d/--destination: 规则针对指定目的地址,支持ip[/mask]-i/--in-interface: 规则针对指定接收数据包的网卡-o/--out-interface: 规则针对指定发送数据包的网卡-m/--match: 加载扩展模块,用于复杂匹配,比较少用-j/--jump: 用于指定数据包匹配规则后的 最终处理动作,或跳转到一个 用户自定义链 继续匹配规则,匹配完毕后回到本链继续执行后续规则。-j ACCEPT: 允许数据包通过-j DROP: 丢弃数据包。不会发送任何响应,客户端会持续等待直到超时,同时也可以避免暴露自身存在,比如拒绝一些 IP 、 端口探测。-j REJECT: 拒绝数据包通过。 返回错误响应。-j my_chain: 跳转到自定义链
-g/--goto: 仅用于跳转到用户自定义链,且 跳转后不会返回原链 。
常见命令
iptables -vnL: 查看所有的 filter 表规则,不反向索引主机名,展示详细信息iptables -t nat -L: 查看所有的 nat 表规则iptables -t filter -A INPUT -s 1.1.1.1 -j ACCEPT-t filter: 指定添加到 filter 表,即配置包过滤功能-A INPUT: 配置 INPUT 链,即接受数据时触发规则-s 1.1.1.1: 指定源地址,当源地址为 1.1.1.1 时,触发规则-j ACCEPT: 规则设置为允许通过
iptables -P INPUT DROP: 配置INPUT链,默认阻止所有访问,仅配置了ACCEPT的规则能通过
iptables 匹配的时候会从链头开始匹配,先匹配到 -j ACCEPT 就直接返回了,因为 -j 指定了 最终处理动作 ,所以后续的 DROP 被忽略了。
iptables -t filter -A INPUT -s 1.1.1.1 -j ACCEPT
iptables -t filter -A INPUT -s 1.1.1.1 -j DROPNAT 表
iptables -t nat -A PREROUTING -i eth0 -d 1.2.3.4 -p tcp --dport 80 -j DNAT --to-destination 192.168.0.111: 目的地址映射。可以将发送给外网的请求映射到内网网关,进行数据采集、转发等工作。-t nat: 配置 nat 表-A PREROUTING: 注册路由处理之前的转发规则-i eth0: 配置监听的网卡-d 1.2.3.4: 配置监听目的 IP 为 1.2.3.4 的数据包-p tcp: 配置监听 TCP 数据包--dport 80: 配置监听发送到 80 端口的数据包-j DNAT: 进行地址转换--to-destination 192.168.0.111: 转换后的目的 IP
iptables -t nat -A POSTROUTING -i eth1 -s 192.168.0.111/24 -p tcp --dport 80 -j SNAT --to-source 1.2.3.4: 源地址映射。可以将内网转发的请求映射伪装成外网发送的。-s 192.168.0.111/24: 指定数据包的源地址字段-j SNAT: 进行源地址转换--to-source 1.2.3.4: 转换后的源地址
持久化规则
iptables 通过命令行添加规则的时候,只会在内存中添加,不会持久化处理,如果需要持久化,可以使用 service iptables save 将当前配置持久化到 /etc/sysconfig/iptables ,如果是 CentOS 7 需要手动安装 iptables-services 。
service iptables save 会调用 iptables-save 获取内存中的规则配置,并保存到临时文件中,再将临时文件重命名为 /etc/sysconfig/iptables 覆盖原配置
firewallD
firewallD 引入了 zone 的概念,将规则链的配置项,比如网段、可访问的服务、网口等信息进行聚合。
在管理时,以 zone 为单位,不需要关注处理的是哪个规则表、哪个规则链,只需要针对不同的 zone 进行管理即可。
ssh
sshd
ssh 是安全远程命令行服务。
早期使用的是 telnet 进行远程命令行,但是由于 telnet 是明文传输,会导致管理员密码泄露,所以才替换为 ssh 。
主要的配置文件在 /etc/ssh/sshd_config ,需要关注的配置有:
Port 22: sshd 监听的端口,默认为 22 ,有些服务器为了安全起见会更改默认端口PermitRootLogin yes: 是否允许 root 用户从 ssh 登录,默认允许AuthorizedKeysFile: sshd 登录的密钥文件放在哪里
配置在修改后需要重启 sshd 才会生效,例如 systemctl restart sshd.service
scp
基于 ssh 协议,扩展出来了文件传输功能,也就是 scp , scp 传输时,命令与文件是使用同一链路传输,这与 FTP 有所区别。
scp ${localFile} ${user}@${server}:${path}: 文件上传。需要交互式的输入密码,或者使用内置密钥scp -i ${keyPath} ${localFile} ${user}@${server}:${path}: 文件上传。指定登录密钥scp ${user}@${server}:${path} ${localFile}: 文件下载。需要交互式的输入密码,或者使用内置密钥scp -r ${localFile} ${user}@${server}:${path}: 目录上传。需要交互式的输入密码,或者使用内置密钥
ftp
简介
FTP 需要使用不同链路传输命令与文件,需要占用至少两个端口:
- 命令传输: 一般使用 20/21 端口进行,比如建立链接,协商文件传输链路端口等。
- 文件传输: 一般使用 > 1024 的端口号,需要通过命令传输将端口号传递给客户端。
命令传输时,分为主动模式与被动模式:
- 主动模式: 建立 FTP 连接后,服务端主动与客户端发送消息,建立文件传输链路
- 被动模式: 建立 FTP 连接后,服务端被动响应客户端消息,建立文件传输链路
可以使用 yum install vsftpd ftp 安装 ftp 功能,并在 systemctl start vsftpd.service 启用 vsftpd 服务。
其中 vsftpd 一般作为服务端, ftp 是客户端。
在安装完成后,可以使用 ftp ${server} 进行 ftp 连接,例如 ftp localhost 。
默认可以使用 ftp 账号登录,密码为空。也支持使用本地账号登录,密码为用户密码。
在连接上 ftp 后,可以使用 !${command} 执行命令,例如 !ls 。
通过 put ${file} 可以将本地的同名文件上传到服务端,文件名保持不变。
通过 get ${file} 可以将服务端的同名文件下载到本地,文件名保持不变。
vsftpd
常见配置文件:
/etc/vsftpd/vsftpd.conf: 主配置文件anonymous_enable=YES: 是否允许匿名用户登录,也就是ftp用户,YES/NO必须大写local_enable=YES: 是否允许使用本地账号登录。write_enable=YES: 是否允许写文件,也就是写入服务端。connect_from_port_20=YES: 是否开启主动传输模式,主动传输一般是 20 端口。userlist_enable=NO: 是否开启用户黑白名单功能。userlist_deny=YES: 为 YES 时, userlist 代表黑名单;为 NO 代表白名单。
/etc/vsftpd/ftpusers: 记录禁止登录的用户,一般是权限较高的用户,避免文件泄露。/etc/vsftpd/user_list: 用户黑白名单配置
虚拟用户
使用本地用户登录 ftp 容易泄露信息,而且在登录时的验证阶段会比较慢,所以往往 ftp 会启用虚拟用户的功能,使用 ftp 专用的账号进行登录。
guest_enable=YES: 开启虚拟用户功能guest_username=vuser: 配置虚拟用户的对应的本地用户,所有 ftp 账号都会使用该账号进行操作,禁止配置为 root 用户user_config_dir=/etc/vsftpd/vuserconfig: 针对每个虚拟用户单独进行权限控制。可以通过此配置修改配置文件存放地址,使用用户名对应配置文件名。allow_writeable_chroot=YES: 允许虚拟用户上传文件pam_service_name=vsftpd.vuser: 修改验证模块名称,使用自定义的验证模块
配置虚拟用户的步骤如下:
# 初始化 ftp 虚拟账号
# 单行为用户名,双行为密码
cat > vuser.temp << EOF
user1
password1
user2
password2
EOF
# 转换为 ftp 数据库文件
db_load -T -t hash -f ./vuser.temp /etc/vsftpd/vuser.db
# 需要更改为 600 权限
chmod 600 /etc/vsftpd/vuser.db
# 修改验证模块,支持使用 FTP 虚拟账号登录
# 需要配置权限验证与登录验证两条记录
# 由于没有保留之前的用户,这种方式验证只能进行虚拟账号登录,无法使用本地账号登录
# 如果需要兼容本地用户,可以在原来的 /etc/pam.d/vsftpd 上修改
cat > /etc/pam.d/vsftpd.vuser << EOF
auth sufficient /lib64/security/pam_userdb.so db=/etc/vsftpd/vuser
account sufficient /lib64/security/pam_userdb.so db=/etc/vsftpd/vuser
EOF
# 初始化用户权限配置目录
mkdir -p /etc/vsftpd/vuserconfig
# 为 user1 配置权限
# local_root: 登录后打开的目录
# write_enable: 是否可写
# anon_umask: 文件权限掩码,用户上传的文件会被设置为 `0777 - anon_umask` 的权限
# anon_world_readable_only: 是否为只读
# anon_upload_enable: 是否可上传
# anon_mkdir_write_enable: 是否允许新建目录
# anon_other_write_enable: 扩展写权限,是否允许支持删除、重命名、覆盖文件等
# download_enable: 是否允许下载
cat > /etc/vsftpd/vuserconfig/user1 << EOF
local_root=/data/ftp
write_enable=YES
anon_umask=022
anon_world_readable_only=NO
anon_upload_enable=YES
anon_mkdir_write_enable=YES
anon_other_write_enable=YES
download_enable=YES
EOF用户态、内核态
用户态即上层应用程序的活动空间,应用程序的执行必须依托于内核提供的资源,包括 CPU 资源、存储资源、 I/O 资源等。为了使上层应用能够访问到这些资源,内核必须为上层应用提供访问的接口,即系统调用。
简单来说:
- 内核态:运行在内核空间的进程的状态
- 用户态:运行在用户空间的进程的状态
区分两种状态的原因在于: 部分 CPU 指令有较大的安全风险,只能在内核中使用,即运行在内核空间,处于内核态; 部分风险不高的指令可以直接暴露给用户,即运行在用户空间,即处于内核态。